26년 4월 1주차 그래프 오마카세
PolyGraph Discrepancy: a classifier-based metric for graph generation
PolyGraph Discrepancy: a classifier-based metric for graph generation
Existing methods for evaluating graph generative models primarily rely on Maximum Mean Discrepancy (MMD) metrics based on graph descriptors. While these metrics can rank generative models, they do not provide an absolute measure of performance. Their values are also highly sensitive to extrinsic parameters, namely kernel and descriptor parametrization, making them incomparable across different graph descriptors. We introduce PolyGraph Discrepancy (PGD), a new evaluation framework that addresses these limitations. It approximates the Jensen-Shannon distance of graph distributions by fitting binary classifiers to distinguish between real and generated graphs, featurized by these descriptors. The data log-likelihood of these classifiers approximates a variational lower bound on the JS distance between the two distributions. Resulting metrics are constrained to the unit interval [0,1] and are comparable across different graph descriptors. We further derive a theoretically grounded summary metric that combines these individual metrics to provide a maximally tight lower bound on the distance for the given descriptors. Thorough experiments demonstrate that PGD provides a more robust and insightful evaluation compared to MMD metrics. The PolyGraph framework for benchmarking graph generative models is made publicly available at https://github.com/BorgwardtLab/polygraph-benchmark.
GitHub - BorgwardtLab/polygraph-benchmark: Benchmarking framework for graph generative models (ICLR 2026)
Benchmarking framework for graph generative models (ICLR 2026) - BorgwardtLab/polygraph-benchmark
Keywords
- Graph Generative Model
- Evaluation Metric
- Polygraph Discrepancy (PGD)
- TabPFN
- 3월달의 오마카세에서 다양한 논문들로 다루어보고자 했던 주제는 GNN의 이론적 통합(MPNN vs Spectral GNN)이나 그래프 표현력의 재해석 (일반그래프 vs 하이퍼그래프)처럼 어떤 모델을 쓸 것인가에 대한 것이었습니다.
- 이번 주 오마카세에서는 질문의 방향을 조금 바꾸어서, 만들어진 모델을 어떻게 제대로 평가할것인가? 라는 실용적인 문제를 다루고자 합니다.
- 좋은 모델을 만드는 일만큼, 그것을 올바르게 측정하는 일 역시 중요합니다. 이러한 문제의식에서 출발하는 이번 논문은, 지금까지 다루어 온 주제들과 자연스럽게 이어지면서도 보다 실용적인 관점을 제공합니다
- 4월 첫째 주 오마카세에서 소개드릴 논문은 그래프 생성 모델(Graph Generative Model, GGM)의 평가 방법을 다룹니다. 그래프 생성 모델을 연구하거나 실무에서 활용하시는 분들께 상당히 유용한 인사이트를 제공하고 있으니 정독해보시길 바랍니다.
- 그래프 생성 모델을 평가할 때 자연스럽게 떠오르는 질문은 다음과 같습니다.
- 이 모델은 실제 그래프를 얼마나 잘 모방하고 있는가?
- 생성된 결과는 얼마나 안정적이며 신뢰할 수 있는가?
- 이미지 생성 분야에는 FID(Frechet Inception Distance)처럼 널리 합의된 평가 지표가 존재하지만, 그래프 분야에서는 오랫동안 MMD(Maximum Mean Discrepancy)라는 지표가 사실상 표준으로 쓰여 왔습니다. 일반적으로 노드 차수 분포, 클러스터링 계수, 라플라시안 스펙트럼 등의 그래프 디스크립터를 추출한 뒤, 실제 그래프와 생성 그래프의 분포 차이를 MMD로 측정합니다.
- 하지만 해당 논문의 저자들은 여기서 중요한 문제를 제기합니다.
💡
우리가 사용해 온 평가 방식 자체가 신뢰할 수 없다면, 모델 비교는 과연 의미가 있을까?
- 실제로 위 질문에 정확하게 대답하는 것은 생각보다 매우 까다롭습니다. 해당 논문에서는 기존 MMD 기반 평가방식에 몇 가지 구조적인 한계를 존재함을 지적하며, 이를 해결하기 위한 새로운 평가 프레임워크PolyGraph Discrepancy(PGD) 를 제안합니다.
- 기존 MMD 기반 평가 방식에는 크게 세 가지 구조적 한계가 있습니다.
- 절대적인 척도가 없음. MMD 값 자체는 커널의 종류와 파라미터 설정에 따라 달라지기 때문에, "MMD = 0.03"이라는 숫자가 좋은 것인지 나쁜 것인지 그 자체로는 판단할 수 없습니다. 서로 다른 디스크립터로 계산된 MMD 값끼리 비교하는 것도 의미가 없습니다.
- 편향과 분산 문제가 심각. 현재 주요 벤치마크에서 통용되는 테스트 그래프 수는 보통 20~40개 수준입니다. 이 논문은 이 정도 샘플 크기에서는 MMD 추정치의 편향과 분산이 모두 너무 커서, 모델 간 순위 비교 자체가 불안정해진다는 것을 실험으로 보입니다.
- 디스크립터 간 통합 점수가 불가능함. 차수 기반 특징과 스펙트럼 기반 특징을 함께 고려하고 싶어도, 여러 MMD 값을 이론적으로 일관되게 결합하는 이론적 근거가 없습니다.
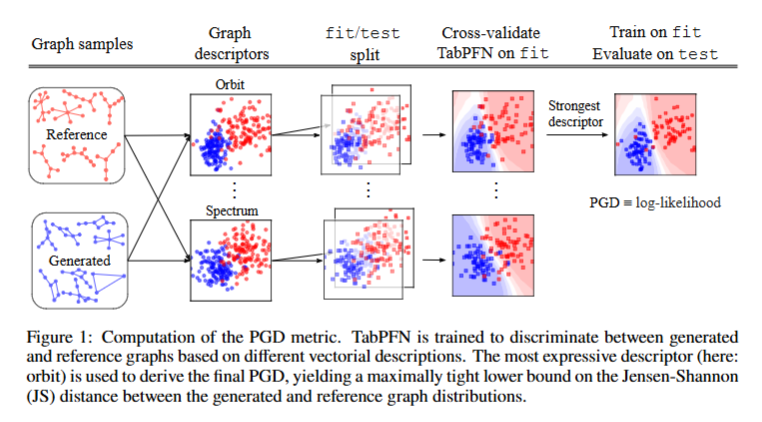
- 이러한 구조적 한계를 해결하기 위한 PGD의 핵심 아이디어는 꽤 간결합니다. GAN 이론에서 잘 알려진 사실처럼, 두 분포 사이의 Jensen-Shannon Divergence(JSD)는 그 두 분포를 구별하는 최적 분류기의 성능과 밀접하게 연결됩니다.
- 즉, 실제 그래프와 생성 그래프를 얼마나 잘 구별할 수 있는가의 해당 분류기의 성능이 곧 두 분포 사이의 거리 정보(하한)를 제공한다, 바로 이 관점을 PGD가 활용합니다.
💡
실제 그래프와 생성 그래프를 얼마나 잘 구별할 수 있는가를 분류기 성능으로 측정하고, 이를 JSD의 하한으로 사용한다.
제안 PSD 평가 절차
- 실제 그래프와 생성 그래프를 각각 여러 디스크립터(차수, 클러스터링 계수, 라플라시안 스펙트럼, orbit count, GIN 임베딩 등)로 벡터화합니다.
- Tabular Prior-data Fitted Network(TabPFN)이라는 Bayesian 추론 기반의 분류기를 사용해 각 디스크립터에 대해 이진 분류를 수행합니다. TabPFN은 하이퍼파라미터 튜닝이 필요 없고 빠르다는 장점이 있습니다.
- 교차 검증으로 가장 판별력이 높은 디스크립터를 선택하고, 해당 디스크립터에 대한 테스트 셋 로그우도를 최종 PGD 점수로 사용합니다. 결과적으로 PGD는 항상 [0, 1] 구간에 위치하며, 이 값은 어떤 디스크립터로 계산하든 동일한 척도로 해석 가능합니다. (0에 가까울수록 실제 분포와 생성 분포가 유사하다는 의미입니다.)
- 여기에서 분류기 선택이 중요한 이유는, 더 강력한 분류기일수록 두 분포를 더 잘 구별하고 따라서 JSD에 대해 더 타이트한 하한을 제공하기 때문입니다. 저자들은 로지스틱 회귀와 TabPFN을 비교해 TabPFN이 일관되게 더 더 강력한 판별력을 만들어낸다는 점을 아래의 3가지 실험을 통해 저자들은 검증하였습니다.
데이터 변형 추적 실험
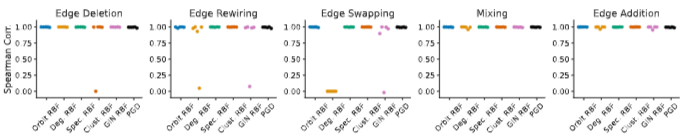
- 실제 그래프 데이터에 엣지 삭제, 엣지 추가, 엣지 재연결, 엣지 교환, 데이터 혼합 등 다섯 가지 유형의 변형을 가하고, PGD와 MMD가 각각 그 정도를 얼마나 잘 추적하는지 Spearman 상관계수로 비교했습니다.
- PGD는 전 유형에 걸쳐 MMD와 동등하거나 더 높은 상관관계를 보였습니다. 특히 차수 보존형 변형인 엣지 교환에서 일부 MMD 지표가 탐지에 실패할 때도 PGD는 여러 디스크립터를 종합해 강건하게 반응했습니다.
학습 진행 추적 실험
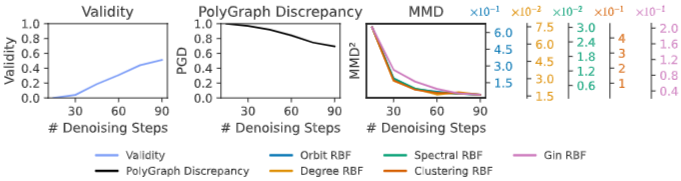
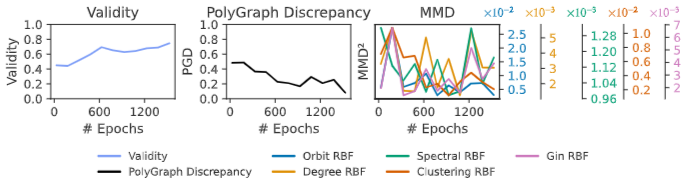
- 최신 확산 모델 DiGress를 대상으로, 디노이징 스텝 수와 학습 에폭 증가에 따라 PGD와 MMD가 모델 품질을 얼마나 잘 반영하는지 살펴봤습니다.
- 그래프 생성 품질의 대표 지표인 Validity(유효 그래프 비율)와의 Pearson 상관관계에서 PGD는 대부분 90% 이상의 상관계수를 기록했으며, MMD 계열 지표들은 경우에 따라 불안정하거나 역상관을 보이기도 했습니다.
모델 벤치마크
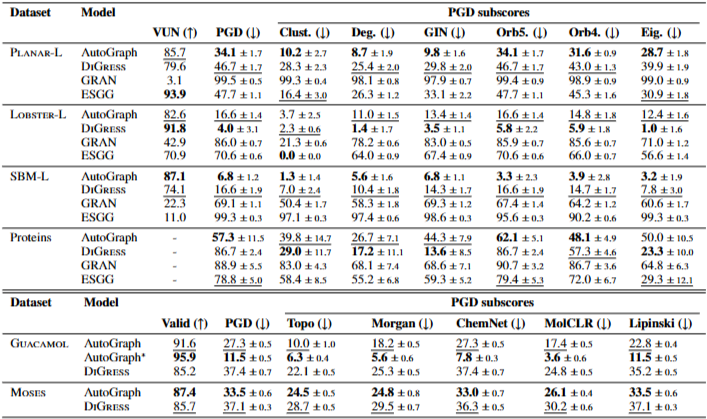
- GRAN, DiGress, ESGG, AutoGraph 등 대표적인 GGM 네 가지를 Planar, SBM, Lobster, Proteins 데이터셋에서 비교한 결과, PGD 순위는 Validity 기반 순위와 전반적으로 일치했으며 MMD보다 더 일관된 모델 비교 결과를 제공했습니다.
- 흥미로운 발견 중 하나는, 어떤 단일 디스크립터도 모든 데이터셋과 변형 유형에 걸쳐 일관되게 가장 좋은 결과를 내지 않는다는 것입니다. 이는 PGD가 여러 디스크립터를 교차 검증으로 선택하도록 설계된 이유이기도 합니다.
- PGD는 단순히 새로운 지표를 제안하는 데 그치지 않습니다.
오랫동안 당연하게 사용되어 온 평가 방식 자체를 다시 질문하고, 이론적으로 해석 가능한 대안을 제시합니다. - 모델 아키텍처 선택이나 그래프 표현 방식에 대해 고민해왔다면, 이 논문은 그 다음 단계인 우리가 얻은 결과를 얼마나 신뢰할 수 있는가?라는 질문에 대한 실용적인 답을 제공합니다.
💡
숫자가 나왔다고 해서 그 숫자를 믿을 수 있는 건 아니다. 평가 지표 자체가 안정적이고, 해석 가능하고, 비교 가능해야 한다.
- 물론 이 논문도 스스로의 한계를 명확히 인정하고 있습니다.
- PGD는 원본 그래프가 아닌 디스크립터 분포를 비교하므로, 디스크립터가 충분한 정보를 담지 못하면 하한이 느슨해질 수 있습니다.
- 또한 TabPFN의 학습 데이터 한계(권장 최대 10k 샘플) 때문에 매우 대규모 벤치마크에서는 추가적인 조정이 필요할 수 있습니다.
- (개인 경험적으로) 이런 벤치마크 관련 논문들을 읽고 나서, 기존 MMD 기반 평가와의 차이를 코드 수준에서 읽어보고 실제 실험을 돌려보며 두 눈으로 직접 비교 및 확인해 나가는 과정이 정말 중요하다고 생각합니다. 이러한 과정을 통해, 제안하는 평가 방법론 자체에 대한 여러분들 각자만의 독보적인 인사이트를 제공할 수 있을 것입니다.
- 그래프 생성 모델을 직접 구현하거나 벤치마크하는 작업을 하고 계시는 구독자분들께 위의 링크로 제공해드린, 공개된 PGD 오픈소스 라이브러리를 직접 활용해보시는 것을 추천드립니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184