26년 6월 1주차 그래프 오마카세
Learning Higher-Order Structure from Incomplete Spatiotemporal Data: Multi-Scale Hypergraph Laplacians with Neural Refinement
Learning Higher-Order Structure from Incomplete Spatiotemporal Data: Multi-Scale Hypergraph Laplacians with Neural Refinement
Sensor networks increasingly govern modern infrastructure, yet the data they lose are rarely missing in the uniform-random patterns assumed by standard imputation benchmarks. Loop detectors go offline during calibration, roadside cabinets silence clusters of nearby sensors, and newly installed instruments provide no history. Such failures create structured absences whose values are constrained by higher-order relations among groups of sensors, not merely by pairwise proximity. Existing low-rank and graph-based methods often miss this collective structure and can fail when missingness becomes coherent. We introduce Multi-Scale Hypergraph Laplacians (MSHL), a two-stage framework for learning higher-order structure from incomplete spatiotemporal observations. The Discovery stage builds a multi-scale hypergraph from complementary topology and residual-correlation evidence, with an observation-only selector that adapts to the supported interaction scale. The Refinement stage adds a small hypergraph-conditioned residual network that is safe by construction: it learns nonlinear corrections where informative residual features exist and defers to the linear estimate where they do not. We prove that MSHL represents group-conservation patterns inaccessible to pairwise graph priors, adapts to the best fixed scale up to a logarithmic factor, transfers this advantage to held-out imputation error, and admits a one-sided refinement guarantee. On two real traffic networks evaluated across scattered cell missingness, contiguous block outages, and whole-sensor blackouts at five rates, MSHL improves over a pairwise-graph baseline whenever higher-order structure is identifiable and otherwise matches it within sampling noise. The results point to a broader principle for reliable infrastructure learning: missing data should be treated not as isolated entries to fill, but as evidence of structure to discover.
Keywords
- Spatiotemporal Imputation
- Hypergraph Laplacian
- Multi-Scale Learning
- Residual Refinement
- 이번 주 오마카세로 전달해드릴 논문은 구조화 결측(Structured missingness)라는 현실적 과제를 해결하는 아이디어를 제안합니다. 교통 센서 네트워크를 대상으로 한 그래프 구조 위에서 어떻게 결측 데이터를 채울 수 있을까? 에 대한 질문과 그 해답을 제공합니다.
- 중요한 점은 이러한 결측이 단순히 우연히 발생하는 것이 아니라는 사실입니다. 네트워크 관점에서 바라보면 결측은 독립적으로 흩어져 발생하는 것이 아니라 특정한 패턴과 구조를 따라 나타나는 경우가 많습니다. 그러나 기존의 많은 결측치 보완(imputation) 기법은 여전히 결측이 무작위로 발생한다는 가정 위에서 설계되어 있습니다. 현실의 센서 네트워크가 보여주는 구조화된 결측(structured missingness)을 충분히 반영하지 못하는 것입니다.
- 기존 그래프 기반 보완 방법들이 쓰는 그래프 라플라시안은 이웃한 두 센서의 값이 비슷해야 한다는 쌍별 제약을 부과합니다. 그런데 현실에서 중요한 제약은 셋 이상의 센서들이 함께 공유하는 흐름 보존(flow conservation) 관계인 경우가 많습니다. 여기에서 바로 하이퍼그래프와 같은 고차 구조정보의 중요성을 찾을 수 있습니다.
- 일반적인 그래프 라플라시안의 quadratic form은 이웃한 두 센서 값의 차이를 최소화하는 방향으로 동작합니다. 여기에서 문제는 세 개 이상의 센서가 하나의 공통 신호를 공유하는 그룹 보존 패턴(group-conservation pattern, Theorem 1)이 존재하는 경우입니다.
- 그룹 보존 패턴의 경우, 그래프 라플라시안은 두 센서 쌍 간의 차이를 따로 보기 때문에 (A-B / B-C 쌍 따로) 모든 센서들이 서로 공유하고 있는 패턴에도 경계 쌍 차이만큼의 불필요한 패널티를 부과하게 됩니다.
- 하지만 이 센서들을 하나의 하이퍼엣지로 묶어 그 패널티를 그룹 내 분산(within-group vaiance)로 부과할 때, 모든 센서가 같은 패턴을 따르는 경우 그 값은 정확히 0이 됩니다. 즉, 하이퍼엣지가 그룹 관계를 정확하게 잡아낼수록, 선형 추정의 편향이 줄어들게 됩니다.
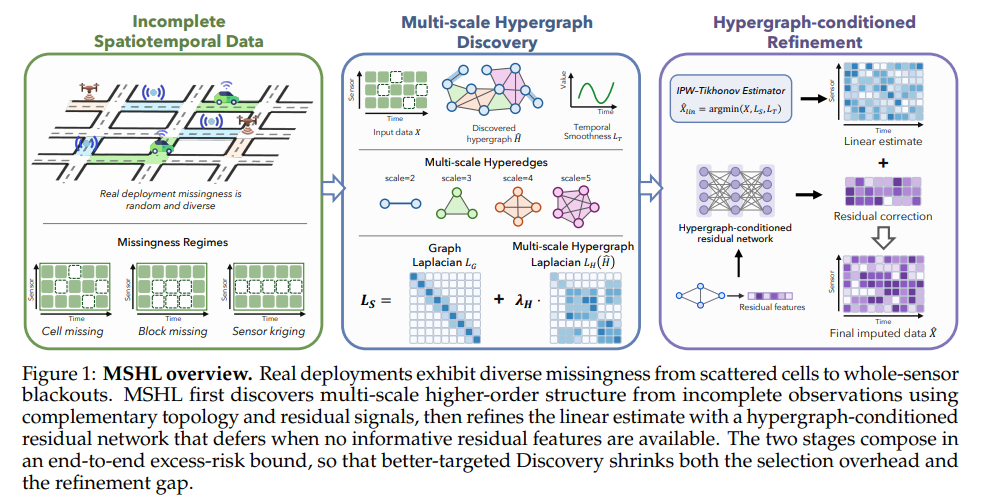
- 논문 저자들이 제안하는 MSHL(Multi-Scale Hypergraph Laplacians)의 전체 파이프라인은 불완전한 데이터에서 하이퍼그래프 구조를 발견하는 Discovery 단계와 그리고 발견된 구조 위에서 선형 추정의 한계를 보완하는 Refinement 단계로 구성됩니다. 두 단계는 서로 피드백을 부여하며 함께 강화되어갑니다.
Multi-scale Hypergraph Discovery
- 센서 네트워크를 포함한 현실의 네트워크에는 다양한 규모의 집단 구조가 공존합니다. MSHL은 이러한 현실을 반영하기 위해 각 스케일의 하이퍼엣지를 동시에 사용하는 다중 스케일 하이퍼그래프 라플라시안(Multi-Scale Hypergraph Laplacian) 을 구성합니다.
- 흥미로운 점은 스케일이 커질수록 특정 규모의 그룹이 과도한 영향력을 갖지 않도록 설계했다는 것입니다. 저자들은 각 스케일의 가중치를 적절히 정규화하여 특정 스케일에 대한 편향적인 선호가 발생하지 않도록 만들었습니다(Lemma 1, Scale Invariance). 이로 인해 하이퍼엣지 하나가 라플라시안 에너지에 기여하는 효과는 그룹의 크기와 무관하게 일관되게 유지됩니다.
- MSHL의 Discovery 단계는 두 가지 상호보완적인 신호를 이용해 하이퍼그래프 구조를 발견합니다. 각각 데이터가 말해주는 구조 및 물리적 네트워크가 제공하는 구조를 활용하는 셈입니다.
- 잔차 소스(Residual Source): 기존 그래프 구조가 설명하지 못한 잔차 패턴에서 숨겨진 집단 구조를 찾습니다.
- 위상 소스(Topology Source): 사전 네트워크 구조를 활용해 후보 하이퍼엣지를 제안합니다.
- 후보 하이퍼엣지가 생성됐다면, 어떤 스케일이 현 데이터에 가장 적합한지를 판단해야 합니다. 스케일을 고정하면 그 크기에 맞지 않는 구조는 놓치고, 너무 크게 잡으면 불필요한 하이퍼엣지가 남게 됩니다. 다음 문제를 풀기 위해 MSHL은 Lepski 원리를 활용합니다.
- Lepski원리의 핵심 아이디어는 여러 스케일의 하이퍼그래프를 후보로 만들고, 각 스케일이 제공하는 설명력과 복잡도를 함께 평가한 뒤, 데이터를 충분히 설명하면서도 가장 단순한 구조를 자동으로 선택하는 것입니다.
- 흥미로운 점은 이 선택 과정이 오직 관측된 데이터만을 사용한다는 사실입니다. 따라서 어떤 결측 체제에서도 미래 정보나 정답을 미리 들여다보는 정보 누수문제가 발생하지 않습니다.
- 저자들은 선택된 스케일이 이상적인 최적 스케일이 달성할 수 있는 성능을 로그 팩터 수준 이내로 추적할 수 있음을 증명합니다 (Theorem 5). 최적의 하이퍼그래프 규모를 미리 알지 못하더라도 성능 손실은 매우 제한적이라는 이론적 강한 보장을 제공합니다.
Hypergraph-Conditioned Refinement
- 이전 Discovery 단계에서 최적의 하이퍼그래프 구조를 찾아냈다고 하더라도, 추정기는 여전히 그래프 라플라시안 기반의 선형 모델입니다. 따라서 집단 구조는 잘 반영할 수 있지만, 실제 데이터에 존재하는 복잡한 비선형 패턴까지 포착하기에는 한계가 있습니다.
- 이를 보완하기 위해 Refinement단계에서는 단순한 HCRN(Hypergraph-Conditioned Residual Network)을 사용합니다. Discovery 단계에서 얻은 선형 추정값을 기본값으로 두고, 얕은 MLP(2-layers)가 잔차값만 추가로 보정하는 방식입니다.
- HCRN의 핵심 설계 철학은 안전한 기본값(default) 입니다. 이는 모델이 자신 있게 보정할 수 있는 상황에서는 비선형 보정을 수행하고, 그렇지 않은 경우에는 억지로 추측하지 않고 선형 백본에 판단을 맡기는 것입니다.
- 입력 특성 벡터는 해당 셀과 동일한 하이퍼엣지에 속한 이웃 센서들의 잔차 정보로만 구성됩니다. 따라서 보정에 활용할 수 있는 관측값이 충분할 때만 비선형 수정이 이루어집니다.
- 반대로 특정 센서가 장기간 완전히 관측되지 않은 경우, 해당 센서와 관련된 잔차 특성을 계산할 수 없으므로 입력 벡터가 사실상 정보 없는 상태가 됩니다. 논문은 이때 HCRN이 보정값을 0으로 수렴시키고 선형 추정값을 그대로 반환함을 보입니다(Lemma 11). 저자들은 이를 automatic deferment 라고 부르며, sensor kriging 실험에서 MSHL이 선형 백본보다 성능이 붕괴하지 않고 거의 동일한 수준을 유지하는 이유입니다.
💡
HCRN의 Worst-case 초과 오차 수렴성 덕분에, 보정할 근거가 없다면 보정하지 않아도 손해가 없다. 이는 앞선 오마카세의 RS-GNN에서 다뤘던 "모를 때는 모른다고 말하는 모델" 과 연결되는 부분입니다.
- 실험은 PEMS-BAY와 METR-LA에서 진행됩니다. 결측 체제는 셀 단위로 독립적으로 빠지는 Cell-MAR, 30분 연속 블록 단위로 빠지는 Block-MAR, 센서 전체가 통째로 빠지는 Sensor Kriging의 세 종류로 구분합니다. 각 체제에서 결측률을 10%부터 90%까지 5단계로 변화시키며 총 30개 조건을 단일 하이퍼파라미터 설정으로 평가합니다.
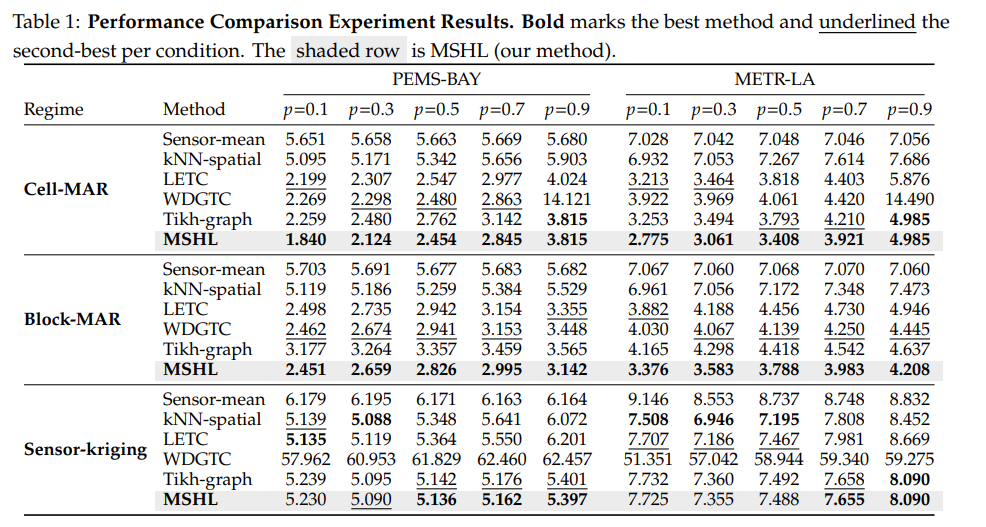
- 가장 인상적인 결과는 Block-MAR의 낮은 결측률 구간입니다. 블록 단위로 여러 센서가 동시에 빠질 때 일반 그래프 페널티는 평활화 대상이 없어 고전하지만, 하이퍼그래프 페널티는 그룹 내 살아남은 다른 시간대의 관측값을 통해 빠진 셀을 일관되게 추론합니다.
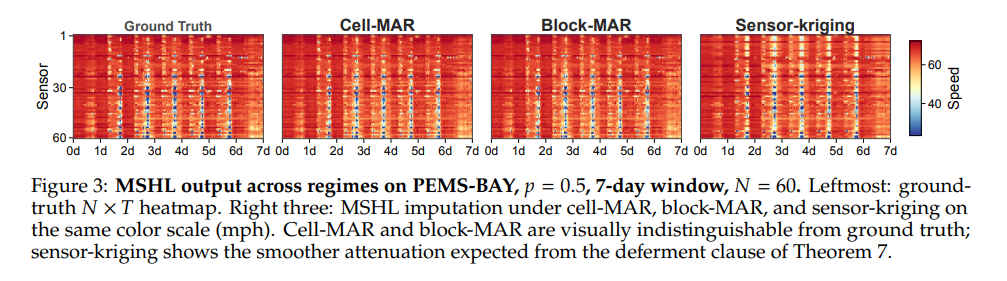
- PEMS-BAY의 60개 센서를 대상으로 히트맵을 세 체제별로 비교하면, Sensor Kriging에서는 빠진 행이 눈에 띄게 매끄럽고, 러시아워의 날카로운 급락이 감쇠됩니다. 논문은 이를 방법의 실패가 아니라 정보 손실이라고 명시합니다. HCRN refinement guarantee (Theorem 7)가 이를 뒷받침합니다.
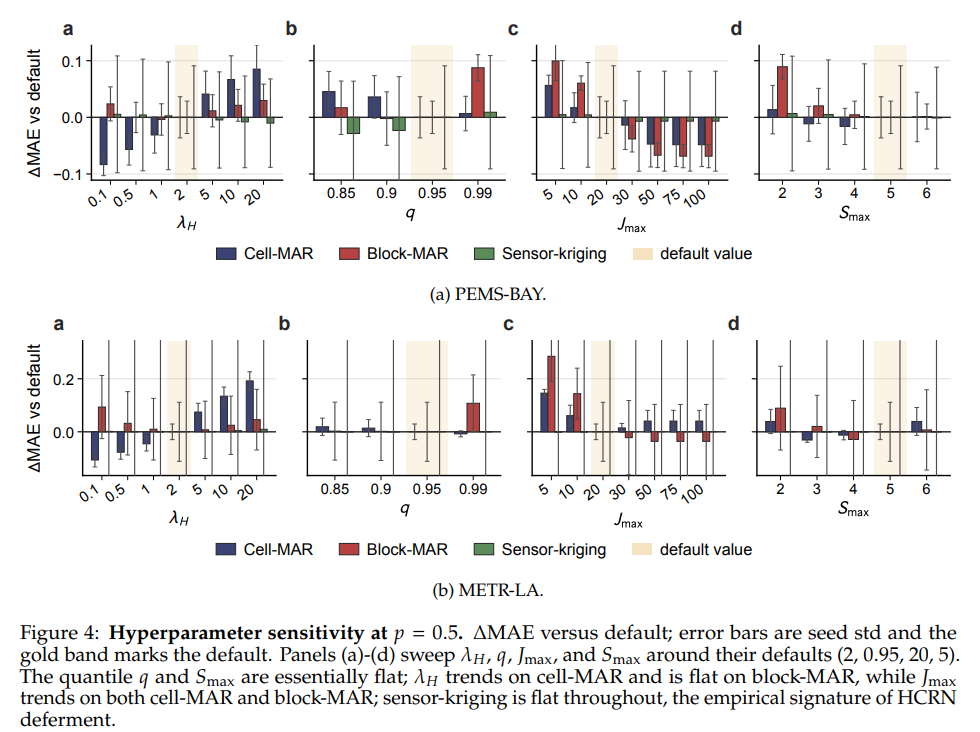
- 주요 하이퍼파라미터 네 가지(분위수 임계값 q, 최대 스케일 S_max, 하이퍼그래프 가중치 λ_H, 후보 상한 J_max)를 p=0.5 조건에서 스윕하는 실험에서 automatic deferment의 경험적 검증이 확인됩니다. 그리고 전반적으로 단일 하이퍼파라미터 설정(λ_H=2, q=0.95, J_max=20, S_max=5)이 두 데이터셋과 세 체제 모두에서 재조정 없이 안정적으로 전달됩니다.
- MSHL이 제시하는 핵심 주장이자, 가장 근본적인 관점 전환은 논문 제목 이전에 Abstract 마지막 문장에 담겨 있습니다.
💡
missing data should be treated not as isolated entries to fill, but as evidence of structure to discover. (결측 데이터는 채워야 할 고립된 항목이 아니라, 발견해야 할 구조의 증거로 다뤄야 한다)
- 결측이 구조화되어있다면 그 보완방법도 구조화되어야 한다는 인사이트를 다중 스케일 하이퍼그래프, Lepski 원리, 그리고 안전장치 (graceful deferment) 세 가지 아이디어로 결합하며 이론적 엄밀성과 실용적 안정성을 동시에 추구한 흥미로운 연구라고 볼 수 있습니다. 결국 이 논문은 결측을 단순히 채워야 할 빈칸이 아니라, 그래프에 숨어 있는 구조를 발견할 수 있는 단서로 바라보고 구조가 충분히 뒷받침될 때만 적극적으로 활용하는 안전한 설계를 택합니다.
- 일부 한계점으로 교통 센서 두 데이터셋의 100개 서브넷 센서에 한정되어 검증되었기에 거대 센서 네트워크에서 Discovery 단계의 계산 복잡도가 어떻게 확장되는 지 검증되어야 합니다. 논문에서는 non-ignorable missingness 문제에서 제안 방법이 적합하지 않음을 명시하고 있습니다.
Reference
- 하이퍼그래프 라플라시안이란 : https://proceedings.neurips.cc/paper/2006/hash/dff8e9c2ac33381546d96deea9922999-Abstract.html
- 그래프 시공간 결측 보완: https://arxiv.org/abs/2108.00298
- Lepski 원리 및 비모수 적응추정 : https://cmao35.math.gatech.edu/pdf/lepski.pdf
- 시공간 교통 예측 문제 (벤치마크 데이터셋) : https://arxiv.org/abs/1707.01926
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184