26년 6월 2주차 그래프 오마카세
Graph Transductive Sharpening: Leveraging Unlabeled Predictions in Node Classification
Graph Transductive Sharpening: Leveraging Unlabeled Predictions in Node Classification
GitHub - transductive-sharpening/tunedGNN: Transductive Sharpening applied on top of the TunedGNN baseline.
Transductive Sharpening applied on top of the TunedGNN baseline. - transductive-sharpening/tunedGNN
Keywords
- Transductive Learning
- Semi-supervised GNN
- Tsallis Entropy
- Entropy Minimization
- 일반적인 Inductive learning에서는 학습 과정에서 보지 못한 새로운 데이터를 얼마나 잘 예측할 수 있는지가 중요합니다. 반면 Transductive learning은 예측 대상이 되는 데이터가 학습 시점에 이미 주어져 있다고 가정합니다. 모델은 주어진 데이터 전체의 구조를 활용하여 레이블이 없는 샘플의 값을 추론합니다.
- GNN의 노드 분류 문제는 대표적인 Semi-supervised Transductive learning 사례입니다. 하나의 그래프가 처음부터 주어지고, 그중 일부 노드에만 레이블이 존재합니다. 모델의 목표는 동일한 그래프 위에 있는 나머지 노드들의 클래스를 예측하는 것입니다. 즉, 학습과 추론이 동일한 그래프 위에서 동시에 이루어집니다.
- 이 때문에 모델은 학습 과정에서 레이블이 없는 노드들에 대해서도 매 스텝마다 예측값을 생성합니다. 하지만 손실 함수는 레이블이 있는 노드에 대해서만 계산되므로, 나머지 노드들의 예측은 학습에 직접 활용되지 않습니다.
💡
모델은 이미 레이블 없는 노드들에 대한 예측을 수행하고 있는데, 그 값이 정말 쓸모없는 정보일까?
만약 모델이 어떤 노드에 대해 충분히 높은 확신을 가지고 있다면, 그 확신 자체를 추가적인 학습 신호로 사용할 수 있지 않을까?
만약 모델이 어떤 노드에 대해 충분히 높은 확신을 가지고 있다면, 그 확신 자체를 추가적인 학습 신호로 사용할 수 있지 않을까?
- 위 질문에 대해 저자들은 Transductive 환경에서 모델은 학습 중에 레이블 없는 노드의 예측값도 이미 만들고 있다는 직관을 손실 함수 수준에서 간단하게 정식화한 Graph Transductive Sharpening(TS)을 소개합니다.
Measure certainty of prediction using Tsallis entropy
- 모델의 예측이 얼마나 확신에 차 있는지를 측정하기 위해 엔트로피 개념을 활용합니다.

- TS의 아이디어 기저는 크로스엔트로피 손실을 예측 분포의 엔트로피 항과 레이블 의존 항의 수학적 분해로부터 직접 도출됩니다. 여기에서 엔트로피 항은 레이블 없이도 계산할 수 있으므로 레이블이 없는 노드에도 최적화 목표를 정의할 수 있다는 이론적 근거를 마련해둡니다.
- 모델의 예측 불확실성을 측정하기 위해 Shannon 엔트로피를 사용하는 것이 직관적이지만 이 엔트로피를 직접 최소화하면 예측 확률이 0 또는 1에 가까워질 때 그래디언트가 급격히 커지며 수치적 불안정성이 발생할 수 있습니다. 여기 Transductive learning 기반의 엔트로피 최소화 기법들이 오랫동안 안고 있던 문제 중 하나인 self-reinforcement 현상 (모델이 지나치게 자신감 있는 예측을 선호하게 되면서 잘못된 예측조차 높은 확신으로 고정)이 발생할 위험이 있습니다.
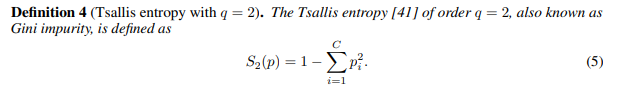
- 저자들은 이 문제를 Tsallis 엔트로피 (q=2)를 사용하며 해결하였습니다. 수식을 보시면 로그 연산이 아닌 단순한 이차 형태로 바뀌어, 확률에 선형적으로 비례하게 되어 작은 확률 영역에서도 발산하지 않습니다. 즉, 확신도가 높아질 수록 Shannon 엔트로피가 가진 수치적 불안정성을 피하면서 예측 분포를 안정적으로 만들어갑니다.
Transductive sharpening objective function

- TS의 목적 함수는 식 (6)과 같이 기존의 크로스엔트로피 손실에 더해 두 개의 정규화 항이 추가됩니다. 다음 정규화 항들은 레이블이 없는 노드에 대해서는 엔트로피를 낮춰 예측을 더욱 확신 있게 만들고, 반대로 레이블이 있는 노드에 대해서는 엔트로피를 높여 과도한 확신을 억제하며 모델의 overconfidence를 조절하기 위한 장치입니다.
- TS의 핵심은 이 두 힘을 동일한 샤프닝 계수 λ로 대칭적으로 적용하는 데 있습니다. 단순히 레이블 없는 노드의 예측만 날카롭게 만들 경우 학습이 쉽게 overconfidence 상태로 치우칠 수 있지만, TS는 이를 제어하는 반대 방향의 힘을 함께 도입하여 안정적인 학습을 유도합니다. 실제로 저자들은 이 대칭 구조를 깨뜨릴 경우 성능이 크게 저하됨을 실험적으로 확인했습니다.
- 저자들은 TS의 효과를 검증하기 위해 다음 네 가지 연구 질문을 설정했습니다.
- TS가 다양한 노드 분류 벤치마크에서 GNN의 성능을 일관되게 향상시키는지 확인
- TS가 MLP에서도 동일한 효과를 보이는지, 나아가 메시지 패싱이 제공하는 이점을 일부 대체할 수 있는지를 분석
- 샤프닝 하이퍼파라미터 λ가 성능에 미치는 영향
- 데이터셋과 모델에 따라 λ를 조정해야 하는지, 아니면 하나의 고정된 λ만으로도 충분한 성능을 얻을 수 있는지
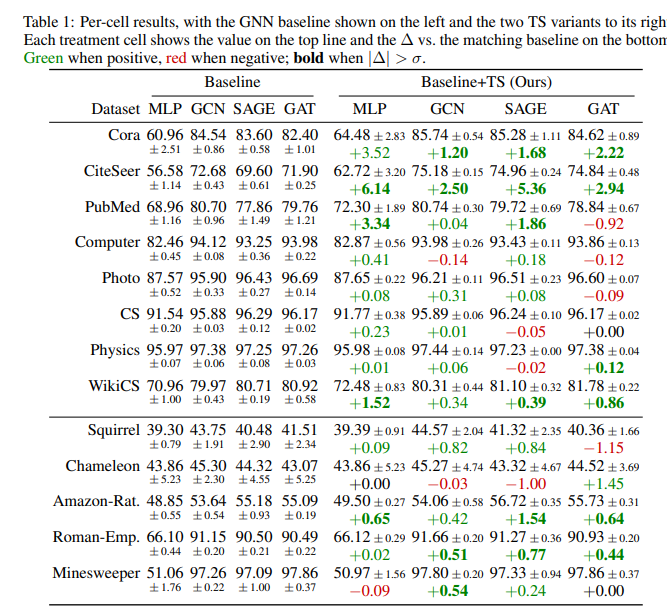
- 4가지 질문에 대한 답을 찾기 위해 13가지 Homo-/Heterophilic 그래프 벤치마크에서 검증하였고, 결과적으로 베이스라인 GNN 모델 전체에서 개선이 광범위하게 일어났으며 메시지 패싱이 없는 단순한 MLP에서도 효과가 있다는 점을 주목합니다. 즉, GNN 아키텍처에 특화된 메커니즘이 아닌 학습 목표 자체의 개선에서 비롯된 결과임을 보여줍니다.
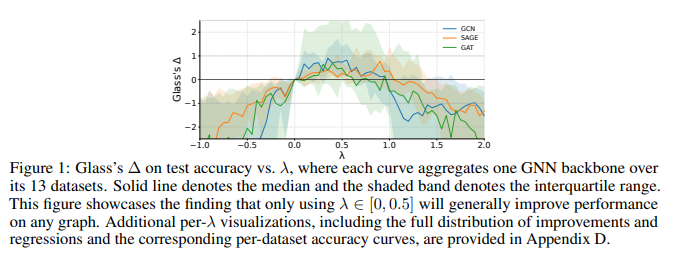
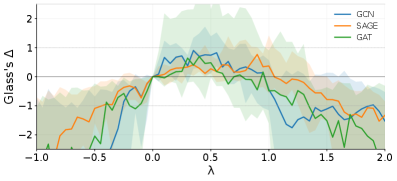
- GCN, GraphSAGE, GAT를 대상으로 λ를 -1.0 ~ 2.0까지 다양한 스케일로 스윕하여 노드 분류의 정확도를 분석한 결과 일관된 패턴이 확인되었습니다.
- 음의 계수 λ에서는 레이블 없는 노드를 더 불확실하게 만드는 방향이므로 대부분의 경우 성능이 하락합니다.
- λ > 0.5에서는 틀린 예측에도 강한 확신을 부여하여 점진적으로 성능이 떨어지는 그래프가 확인됩니다. 특히 >1에서 큰 기울기 하락이 두드러집니다.
- 실험적으로 0 ~ 0.5 사이 값에서 13개 데이터셋 성능이 기준선 이상을 유지되었으며, 0.25의 median 값으로 기본값을 설정하여 데이터셋별 튜닝 없이 대부분의 조건에서 성능 유지 또는 개선할 수 있음을 보여줍니다.
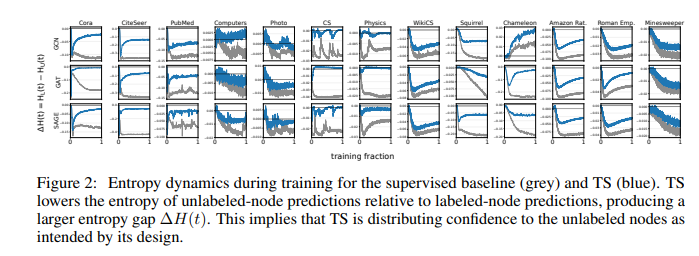
- 학습 과정동안 레이블이 있는 노드와 없는 노드 각각의 평균 엔트로피 동역학적 변화를 추적하였을 때, 적당한 λ는 레이블 없는 노드의 신뢰할 만한 예측만을 학습 신호로 활용하게 만들지만, λ가 너무 커지면 아직 검증되지 않은 예측까지 강제로 확신하게 됩니다. 결국 모델은 자신의 오류를 스스로 강화하며 잘못된 방향으로 굳어질 수 있습니다.
💡
모델 학습 중에 레이블 없는 노드의 예측값도 쓸모 없는 것이 아닙니다.
다만 레이블 있는 노드에서 과잉 확신을 동시에 줄여야 두 힘이 균형을 이루고 학습이 안정됩니다.
다만 레이블 있는 노드에서 과잉 확신을 동시에 줄여야 두 힘이 균형을 이루고 학습이 안정됩니다.
- TS는 학습 중 Transductive 설정 덕분에 레이블이 없더라도 모델이 어떤 노드에 대해 이미 높은 확신을 갖고 있다면 그 확신 자체를 새로운 학습 신호로 재활용할 수 있다는 직관을 이론적으로 실험적으로 보여줍니다.
- 모델 예측에 대한 확신을 무조건 강화하는 대신, 엔트로피를 통해 확신도를 측정하고 이를 강화하거나 억제하는 균형 메커니즘을 도입하여 안정적인 학습을 유도합니다. 그 결과 다양한 그래프 벤치마크에서 일관된 성능 향상을 달성했으며, 그래프 구조를 활용하지 않는 MLP에서도 유의미한 성능 개선을 보여주었습니다.
- 물론 모든 환경에서 동일한 효과를 보이는 것은 아닙니다. 개선 폭이 크게 나타난 CiteSeer, Cora 등의 데이터셋은 비교적 레이블 비율이 낮고 노드 수가 적은 경향이 있었으며, 이미 성능이 높은 CS, Physics 등에서는 추가적인 이득이 제한적이었습니다.
- 또한 Heterophilic 그래프에서는 이웃 노드 간 클래스 불일치가 빈번하기 때문에, 메시지 패싱을 통해 전달된 예측 자체의 신뢰도가 낮아져 Homophilic 그래프만큼 일관된 개선 효과를 보이지는 않았습니다.
- TS는 기존 노드 분류의 성능 향상을 위한 모델 아키텍처를 새롭게 설계하는 대신, 잘 튜닝된 기존 아키텍처를 베이스라인으로 두고 이들의 학습 과정에서 이미 생성되고 있는 예측을 어떻게 활용할 것인가에 주목한 점이 인상적입니다. 그로부터 목적 함수에 하이퍼파라미터 1개를 대칭적으로 추가하는 것만으로도 낮은 비용으로 의미 있는 성능 개선을 보였다는 점에서 복잡한 아이디어가 항상 옳지 않음을 다시 한번 보여주는 사례라고 생각합니다.
Reference
- 반지도학습과 엔트로피 최소화 방법 시초논문 : https://proceedings.neurips.cc/paper_files/paper/2004/file/96f2b50b5d3613adf9c27049b2a888c7-Paper.pdf
- 잘 튜닝된 고전 GNN의 강점, 학습 목표 설정의 중요성 : https://openreview.net/forum?id=xkljKdGe4E#discussion
- TS의 대칭적 구조 설계 : https://proceedings.neurips.cc/paper_files/paper/2019/file/f1748d6b0fd9d439f71450117eba2725-Paper.pdf
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184