26년 5월 2주차 그래프 오마카세
Deep GraphRAG: A Balanced Approach to Hierarchical Retrieval and Adaptive Integration
Deep GraphRAG: A Balanced Approach to Hierarchical Retrieval and Adaptive Integration
Graph-based Retrieval-Augmented Generation (GraphRAG) frameworks face a trade-off between the comprehensiveness of global search and the efficiency of local search. Existing methods are often challenged by navigating large-scale hierarchical graphs, optimizing retrieval paths, and balancing exploration-exploitation dynamics, frequently lacking robust multi-stage re-ranking. To overcome these deficits, we propose Deep GraphRAG, a framework designed for a balanced approach to hierarchical retrieval and adaptive integration. It introduces a hierarchical global-to-local retrieval strategy that integrates macroscopic inter-community and microscopic intra-community contextual relations. This strategy employs a three-stage process: (1) inter-community filtering, which prunes the search space using local context; (2) community-level refinement, which prioritizes relevant subgraphs via entity-interaction analysis; and (3) entity-level fine-grained search within target communities. A beam search-optimized dynamic re-ranking module guides this process, continuously filtering candidates to balance efficiency and global comprehensiveness. Deep GraphRAG also features a Knowledge Integration Module leveraging a compact LLM, trained with Dynamic Weighting Reward GRPO (DW-GRPO). This novel reinforcement learning approach dynamically adjusts reward weights to balance three key objectives: relevance, faithfulness, and conciseness. This training enables compact models (1.5B) to approach the performance of large models (70B) in the integration task. Evaluations on Natural Questions and HotpotQA demonstrate that Deep GraphRAG significantly outperforms baseline graph retrieval methods in both accuracy and efficiency.
GitHub - liunian-Jay/Awesome-RAG: 💡 Awesome RAG: A resource of Retrieval-Augmented Generation (RAG) for LLMs, focusing on the development of technology.
💡 Awesome RAG: A resource of Retrieval-Augmented Generation (RAG) for LLMs, focusing on the development of technology. - liunian-Jay/Awesome-RAG
Keywords
- GraphRAG
- Hierarchical Retrieval
- Beam Search
- Reinforcement Learning
- LLM Distillation
- 최근 몇 년간 AI 산업에서 LLM의 활용 방식은, 초기 사전학습된 모델이 가진 파라미터 안의 지식에만 의존했다면, 이제는 외부 데이터베이스나 문서를 실시간으로 참조해서 답변하는 RAG방식이 사실상 산업 표준에 가깝게 자리를 잡았습니다.
- 그런데 이 RAG라는 패러다임이 한 단계 더 발전하는 흐름이 생겼습니다. 단순히 벡터 유사도로 관련 청크를 끌어오는 방식에서, 엔티티와 관계를 명시적으로 표현하는 지식 그래프를 결합한 GraphRAG로의 전환이 그것입니다. 구조화된 지식 위에서 추론하면 다층적 관계와 그 맥락을 훨씬 풍부하게 포착할 수 있다는 이점을 얻을 수 있습니다.
- 하지만 이 GraphRAG 접근법에도 오랫동안 해결되지 않은 고질적인 딜레마가 존재합니다.
💡
전체를 넓게 훑으면 정확도가 떨어지고, 좁고 깊게 파고들면 속도가 느려진다. 기존 GraphRAG는 이 트레이드오프 사이에서 늘 타협하고 있습니다.
- Microsoft Research가 제안한 Global Search 방식처럼 그래프 전체를 커뮤니티 단위로 요약하는 접근은 넓은 시야를 확보하지만, Map-Reduce 방식의 특성상 세부 사실이 희석되고 검색 지연이 크게 늘어납니다. 반대로 특정 엔티티 주변만 좁게 파고드는 Local Search 방식은 속도는 빠르지만, 여러 커뮤니티에 걸친 복잡한 추론 질의에는 힘을 쓰지 못합니다.
- 이번 주 오마카세에서 소개해드릴 논문 Deep GraphRAG는 바로 이 지점에 정면으로 도전합니다. 이 논문이 참신하다고 생각되었던 이유는 크게 두 가지입니다.
- 첫 번째는 기술적 접근의 참신함입니다. 정보 검색 분야에서 익숙한 빔 서치(Beam Search) 알고리즘을 그래프의 계층적 커뮤니티 구조 탐색에 접목한 방식은, 지금까지 GraphRAG 연구에서 시도된 적이 없는 독창적인 결합입니다.
- 두 번째는 실용성의 문제입니다. LLM을 실제 서비스에 적용할 때 항상 발목을 잡는 요소 중 하나가 추론 비용입니다. 이 논문은 강화학습 기반 학습 방법론(DW-GRPO)을 통해 1.5B 소형 모델이 지식 통합 단계에서 72B 대형 모델의 94% 수준 성능을 낼 수 있음을 보여줍니다.
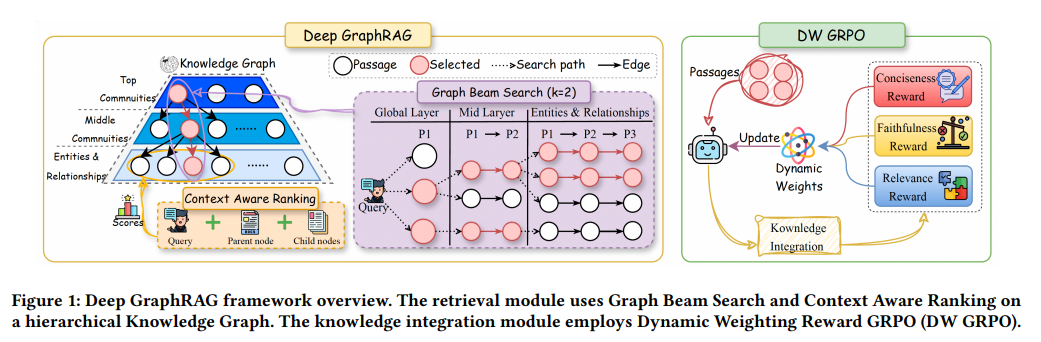
- Deep GraphRAG의 전체 프레임워크는 크게 두 개의 모듈로 나뉩니다.
- 하나는 지식 그래프를 계층적으로 구성하고 빔 서치 기반으로 탐색하는 검색 모듈(Retrieval Module)이고, 다른 하나는 검색된 결과를 소형 LLM이 효율적으로 통합해 최종 답변을 생성하는 지식 통합 모듈(Knowledge Integration Module)입니다. 서로 독립적으로 설계되었지만, 실제로는 서로 긴밀하게 연결되어 전체 파이프라인의 성능을 결정합니다.
계층적 지식 그래프 구성 (Hierarchical KG Construction)
- 모든 것은 원본 코퍼스를 그래프로 변환하는 단계에서 시작합니다.
- Text Chunking and Extraction
- 텍스트를 600토큰 단위의 슬라이딩 윈도우로 분할하되, 앞뒤 청크 간 100토큰을 겹치게 해서 경계 구간의 정보 손실을 최소화합니다. 각 청크에서는 Qwen2.5-72B-Instruct를 활용해 엔티티와 방향성 관계를 추출합니다.
- 이때 기존의 단순 트리플(주어-서술어-목적어) 방식과 달리, 각 엣지에 자연어 설명을 함께 생성하도록 강제합니다. 관계의 의미를 좀 더 풍부하게 담기 위한 선택입니다.
- Entity Resolution
- 엔티티 해석 단계에서는 유사한 엔티티를 병합하는 과정이 필요합니다. 단순히 문자열이 같은 엔티티를 병합하는 방식은 표기 변형에 취약하기 때문에, 이 논문은 두 단계 검증을 사용합니다.
- 먼저 bge-m3 임베딩 모델로 각 엔티티 설명의 코사인 유사도를 계산해 τ > 0.95 이상인 후보 쌍을 추립니다. 그리고 해당 쌍을 LLM이 다시 검토해 실제로 같은 실세계 개념을 지칭하는지 최종 판단합니다. "U.S."와 "United States"처럼 축약어 표현의 동일한 개념을 정확하게 병합하기 위함입니다.
- Hierarchy Generation
- 정제된 기본 그래프 위에 가중 Louvain 알고리즘(해상도 파라미터 γ = 1.0)을 반복 적용해 3단계 커뮤니티 계층 (0: 개별 엔티티, 1: 엔티티들의 소커뮤니티, 2: 다음 커뮤니티를 묶은 대커뮤니티) 을 구성합니다.
- 각 커뮤니티의 임베딩은 하위 커뮤니티 벡터들의 평균 풀링으로 생성되며, 각 노드의 임베딩은 해당 노드의 로컬 설명에 부모 커뮤니티 벡터를 이어붙이는 방식으로 구성됩니다. 개별 엔티티가 속한 맥락 정보를 임베딩 단계에서부터 내포하는 것이 핵심입니다.
3단계 빔 서치 기반 검색

- Deep GraphRAG 알고리즘의 핵심 설계는 방대한 그래프 전체를 탐색하지 않으면서도 전역적인 맥락을 잃지 않는 균형을 빔 서치로 확보하는 것입니다.
💡
빔 서치는 각 단계에서 상위 k개 후보만 유지하며 불필요한 탐색을 가지치기하면서도, 그래프의 계층 구조를 따라 전역에서 로컬로 내려오는 하향식 구조 덕분에 글로벌 컨텍스트를 잃지 않고 엔티티 수준의 정밀도까지 도달할 수 있다는 장점이 있습니다.
- 쿼리가 들어오면 최상위 커뮤니티부터 시작해 개별 엔티티까지 하향식으로 탐색하는데, 매 단계마다 빔 너비(k=3)를 유지하며 가장 유망한 후보만 남기고 나머지는 탐색 경로에서 제외합니다.
- 1단계(커뮤니티 필터링)에서는 최상위 커뮤니티 전체를 Re-ranker로 빠르게 스코어링해 상위 k개를 선별합니다. 여기서는 세밀한 의미 매칭보다 속도를 우선시합니다.
- 2단계(서브커뮤니티 정제)에서는 선별된 커뮤니티를 하위 커뮤니티로 펼쳐 bge-reranker-v2-m3를 사용한 정교한 의미 매칭을 수행합니다. 이때 부모 커뮤니티의 벡터와 자식 커뮤니티의 벡터를 결합해 쿼리와 비교함으로써, 자식 커뮤니티를 맥락 속에서 평가합니다.
- 3단계(엔티티 정밀 검색)에서는 최종 목적지인 개별 엔티티 수준에서 검색이 이루어집니다. 여기서 중요한 설계 선택이 하나 있습니다. 해당 엔티티의 임베딩에 부모 커뮤니티 벡터를 Concat하여 새로운 문맥 인식 표현을 만든 뒤 코사인 유사도를 계산합니다.
DW-GRPO — 동적 보상 가중치 강화학습
- 검색 이후 단계의 과제는 찾아온 정보를 어떻게 효율적으로 통합할 것인가입니다. 해당 저자들은 비용과 속도 모두를 잡기 위해 지식 통합(Knowledge Integration) 단계를 별도 모듈로 분리하고, 이 모듈에 1.5B 소형 모델을 사용합니다.
- 문제는 소형 모델이 대형 모델 수준의 통합 품질을 어떻게 달성하느냐입니다. 이 답이 바로 DW-GRPO(Dynamic Weighting Reward GRPO)입니다.
- 기존 GRPO는 각 보상 항목에 고정된 가중치를 부여하는데, 이 부분이 최적화하기 어려운 목표는 정체 상태에 빠뜨리는 원인이 됩니다.
- 논문은 이를 시소효과 (seesaw effect) 라고 부릅니다. 시소의 어느 한쪽이 올라가면 다른 한쪽은 내려가는 상황처럼, 최적화가 쉬운 간결성이 학습 초반에 빠르게 포화되면, 해당 모델은 짧고 간결하게 쓰는 법을 배우지만 여전히 정확한 말을 하는 법을 모르는 상태에 빠진 것을 나타냅니다.
- DW-GRPO는 이 문제를 동적 가중치 조정으로 해결합니다. 훈련이 진행되는 동안 각 보상 항목의 성장 속도를 실시간으로 추적하고, 성장이 느린 항목에 더 높은 가중치를 자동으로 부여합니다.
- 슬라이딩 윈도우 내에서 각 보상의 선형 회귀 기울기를 계산하고, 이를 정규화한 뒤 softmax 함수로 가중치를 산출합니다.
- 기울기가 낮을수록 해당 보상의 가중치가 올라가는 구조입니다.
- DW-GRPO가 최적화하는 세가지 보상은 다음과 같습니다.
- 관련성(Relevance, r_rel) : 생성된 지식 통합 결과가 쿼리에 얼마나 잘 답하는지를 측정합니다. bge-reranker-v2-m3 크로스인코더 모델로 쿼리-출력 쌍의 점수를 계산합니다.
- 사실 충실도(Faithfulness, r_faith) : 생성 결과가 원본 지식 내용에 얼마나 충실한지를 측정합니다. bge-m3 기반 BERTScore의 F1 점수를 활용합니다.
- 간결성(Conciseness, r_conc) : 불필요한 장황함을 억제합니다. 생성 결과 길이를 원본 텍스트 길이로 정규화한 길이 기반 보상입니다.
- 훈련 파이프라인은 2단계로 구성됩니다.
- 먼저 Qwen2.5-72B 대형 모델이 생성한 출력을 라벨로 사용해 Qwen2.5-1.5B 소형 모델을 SFT로 초기화합니다. 이후 DW-GRPO로 강화학습을 적용합니다.
- SFT가 좋은 시작점을 제공하고, DW-GRPO가 세 가지 목표를 균형 있게 최적화하면서 소형 모델의 성능을 끌어올리는 구조입니다.
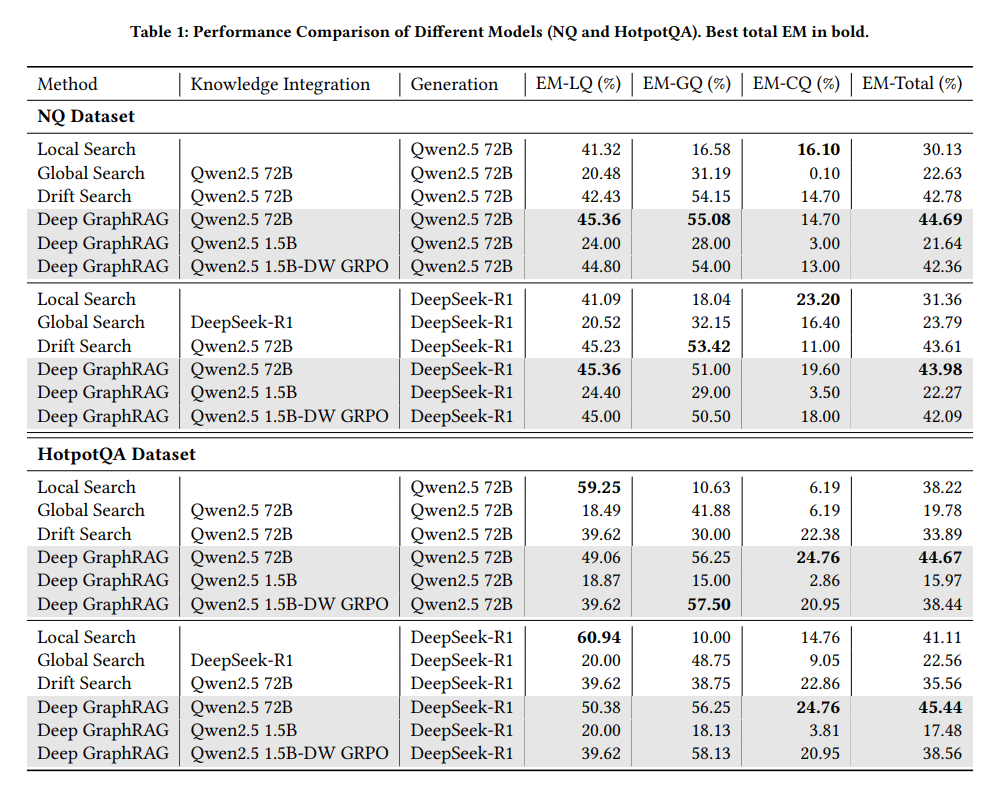
- 실험은 Natural Questions(NQ)와 HotpotQA 두 벤치마크에서 진행합니다. 질문은 1~2개 노드에서 직접 답을 찾을 수 있는 로컬 질문(LQ), 여러 커뮤니티에 걸친 다중 엔티티 추론이 필요한 글로벌 질문(GQ), 그리고 두 가지 성격을 모두 요구하는 종합 질문(CQ)의 세가지 유형으로 구분됩니다.
- 가장 명시적인 결과는 GQ에서의 압도적 우위를 달성했다는 점입니다. 멀티홉 추론처럼 여러 커뮤니티에 걸친 정보를 연결해야 하는 질의에서 계층적 탐색의 강점이 가장 명확하게 드러나는 결과입니다.
- HotpotQA의 GQ 유형에서 Deep GraphRAG(72B 통합)는 56.25%의 EM을 기록한 반면, Local Search는 10.00%, DRIFT Search는 38.75%에 그쳤습니다.
- DW-GRPO의 효과도 수치로 확인됩니다. 표준 GRPO를 적용한 1.5B 모델 대비 DW-GRPO 적용 모델이 일관되게 높은 성능을 보이며, NQ 전체 EM 기준으로 72B 모델(44.69%)의 약 94%에 해당하는 42.36%를 달성합니다.
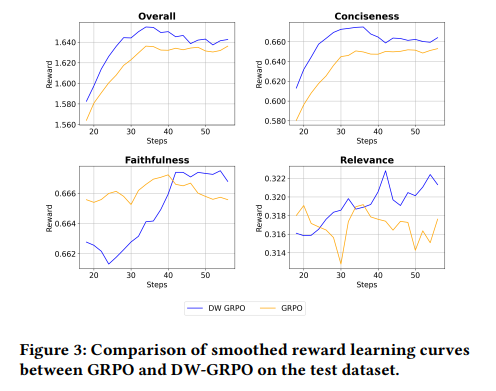
- 보상 학습 곡선을 보면, 표준 GRPO에서는 간결성 보상은 빠르게 포화되지만 관련성과 사실 충실도 보상은 낮은 수준에서 정체되는 시소 효과가 명확히 관찰됩니다. DW-GRPO는 세 보상 모두 꾸준히 향상되는 균형 잡힌 학습 곡선을 보여줍니다.
- Deep GraphRAG는 GraphRAG 연구에서 오랫동안 풀리지 않던 트레이드오프를 계층적 빔 서치라는 방식으로 정면 돌파한 논문입니다.
- DRIFT Search 대비 로컬 질문에서 86%, 글로벌 질문에서 81.6%의 지연 시간을 줄이면서도 정확도는 오히려 개선했다는 결과는, 전체를 보려면 느려야 한다는 기존 상식에서 벗어나 계층 구조를 잘 활용하면 속도와 정밀도가 반드시 교환 관계에 있지는 않다는 것을 보여줍니다.
- DW-GRPO의 기여도 주목할 만합니다. 강화학습에서 다중 보상을 균형 있게 최적화하는 문제는 이미 멀티태스크 학습 분야에서 오랫동안 연구된 주제인데, 이 논문은 그 아이디어를 LLM 파인튜닝의 맥락에 가져와 보상 항목별 성장 속도를 실시간으로 추적해 가중치를 조정하는 방식으로 구현하였습니다.
- 결과적으로 1.5B 소형 모델이 지식 통합이라는 특정 태스크에서 72B 모델을 거의 따라잡는다는 사실은, 대형 모델이 반드시 필요한 단계와 소형 모델로 충분한 단계를 파이프라인 내에서 분리하는 전략이 현실적임을 시사합니다.
💡
어떤 단계에 어떤 크기의 모델을 배치할 것인가. 이 논문은 그 결정이 단순한 비용 최적화의 문제가 아니라, 태스크의 성격과 훈련 방법론에 달린 설계 문제임을 보여줍니다.
- 저희와 같은 연구자 관점에서, 이 논문이 제시하는 그래프 구성 방식 자체도 흥미롭습니다. 지식 그래프를 어떻게 구성하고, 그 위에서 어떤 계층 구조를 정의하며, 어떤 방식으로 정보를 집계하는가의 문제가 결국 이전 오마카세에서 다뤄온 GSO(Graph Shift Operator) 설계 문제와 같은 맥락에 놓여 있다고 해석해볼 수 있습니다.
- 정량적 성능의 한계도 눈여겨볼 필요가 있습니다. 가장 크게, 종합 질문(CQ) 유형에서는 모든 베이스라인을 압도하지 못합니다.
- NQ 데이터셋에서 DeepSeek-R1 생성 모델을 사용한 경우, Local Search의 CQ EM이 23.20%인 반면 Deep GraphRAG는 19.60%에 그쳤습니다.
- 저자들은 계층적 요약 과정에서 세부 사실이 지나치게 추상화되는 것이 원인이라고 지목합니다. 전체 구조를 위에서 아래로 탐색하는 설계의 강점이, 동시에 특정 유형의 쿼리에서는 약점으로 작용하는 셈입니다.
- 향후 연구 과제로 글로벌 요약과 로컬 사실 보존 사이의 균형을 개선하는 방향을 결론의 마지막 문장으로 명시하고 있습니다.
- 인사이트를 간략하게 정리해보자면, 이 논문은 GraphRAG 연구가 단순히 더 큰 모델, 더 많은 그래프 노드라는 방향이 아니라 구조를 잘 정의하고 그 위에서 어떤 탐색 전략을 취할 것인가라는 방향으로 진화하고 있음을 보여주는 좋은 사례로 보입니다.
- 계층적 커뮤니티 구조 위에서 하향식 탐색을 설계하고, 엔티티 임베딩에 부모 커뮤니티 벡터를 결합해 문맥 인식 표현을 만드는 방식, 그리고 다중 보상을 동적으로 균형 있게 학습하는 DW-GRPO는 각각 독립적으로도 충분히 참고할 만한 아이디어입니다.
- GraphRAG 파이프라인 구축에 있어서 강화학습 기반 LLM 추론 비용 절감 방법을 탐색 중이시거나 소형 모델을 효율적으로 파인튜닝하는 것에 관심 있으신 분들에게 가볍게 읽기 좋은 논문입니다.
Reference
- Global Search, Microsoft : https://microsoft.github.io/graphrag/query/global_search/
- Louvain 알고리즘, Medium : https://medium.com/@hon9hb/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-louvain-algorithm-%EC%86%8C%EA%B0%9C-5d59b2b53c7c
- Re-ranker란, Devocean(SKT) : https://devocean.sk.com/blog/techBoardDetail.do?ID=167335&boardType=techBlog
- Seesaw 효과, 논문 참고문헌 : https://dl.acm.org/doi/abs/10.1145/3383313.3412236
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184