4월 3주차 그래프 오마카세

Twitter Recommendation algorithm
[https://github.com/twitter/the-algorithm]
twitter graph 알고리즘 특집입니다. 정리 요약본을 보시려면
[https://newsletter.theaiedge.io/p/how-twitter-and-tiktok-recommend] 게시물을 추천드립니다.
트위터에서 알고리즘을 오픈했죠. 이 사례가 무엇을 함의하고 있는가를 고민해본 결과 두 가지 결론을 내리게 되었습니다. 1. [SNS계의 ESG] 자칫하면 정보의 편향성과 왜곡을 불러일으킬 수 있는 SNS에서 알고리즘 오픈을 통해 유저에게 가치있고 다양한 정보를 제공하고자 하는 진정성 어필. 2. [Graph can analytics in product] ‘Graph가 제품에서 작동할 수 있나요?’ 고객들의 의문에 대해 명쾌하게 답변할 수 있고 참고할 수 있는 사례.
트위터를 이용할 때, 나에게 추천되는 결과물에 대해 궁금하셨던 분들 그리고 실제 현업에서 그래프를 활용하기 위해 아키텍쳐를 고민하고 계시는 DBA 분들에게 많은 도움이 될 거라 생각됩니다.
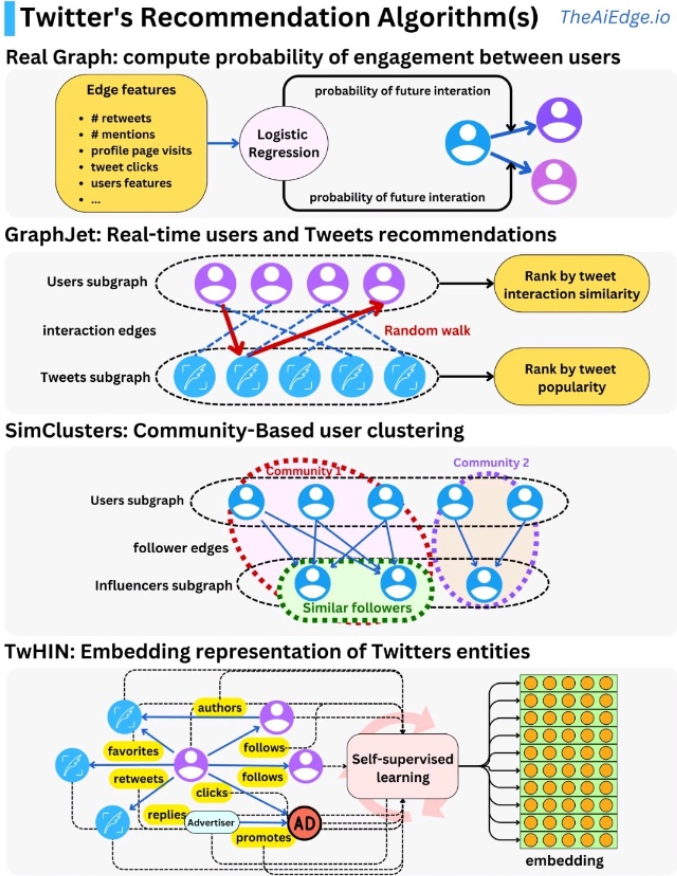
UserTweetEntityGraph (UTEG)
What is it
User Tweet Entity Graph (UTEG) is a Finalge thrift service built on the GraphJet framework. It maintains a graph of user-tweet relationships and serves user recommendations based on traversals in this graph.
How is it used on Twitter
UTEG generates the "XXX Liked" out-of-network tweets seen on Twitter's Home Timeline. The core idea behind UTEG is collaborative filtering. UTEG takes a user's weighted follow graph (i.e a list of weighted userIds) as input, performs efficient traversal & aggregation, and returns the top-weighted tweets engaged based on # of users that engaged the tweet, as well as the engaged users' weights.
UTEG is a stateful service and relies on a Kafka stream to ingest & persist states. It maintains in-memory user engagements over the past 24-48 hours. Older events are dropped and GC'ed.
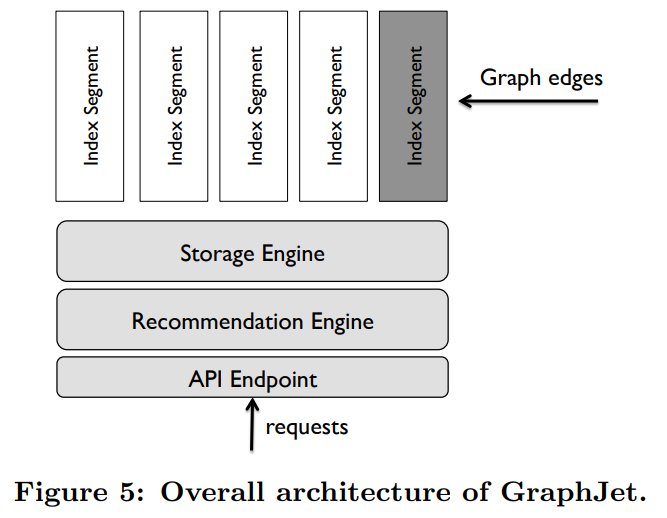
For full details on storage & processing, please check out our open-sourced project GraphJet, a general-purpose high-performance in-memory storage engine.
GraphJet: Real-Time Content Recommendations at Twitter
[http://www.vldb.org/pvldb/vol9/p1281-sharma.pdf]
Summary
- 트위터 하면 무엇이 생각나시나요? 저는 많은 요소들이 있겠지만, 그 중에서도 단연 실시간성 정보교류라고 생각합니다. 한 트윗당 280자 이내로 정보를 전달해야하기에, 당연하게도 핵심정보만 Compact 하게 잘 작성해야 더욱 사람들에게 노출되기 쉽습니다.
- 그렇다면, 결국 트위터는 이 ‘실시간성’을 어떻게 잘 가공해서 유저에게 추천을 할까? 라는 문제에 당면하게 됩니다. 굉장히 복잡하고 많은 리소스들이 투입될거라 예상했던 제 생각과는 다르게, 트위터는 이를 API 형태로 해결을 합니다. 물론, 이전의 시도들(DB , HDFS 등)이 존재했기에 API all-in-one 까지 이룰수 있지않았을까 싶네요.
- 저는 그래프 추천에 관심이 많기에 Storage engine → Recommendation engine 까지 어떻게 구성되어있는가를 중점을 두며 논문을 살펴봤습니다. 그 내용을 간략히 말씀드려보자면, 1.Bipartite (user-tweet) 형태로 그래프를 모델링하여 analytics(ego random-walk 등)을 활용하여 각자 노드들마다 scoring 을 해줍니다. 2. 그리고 그 결과들을 Storage Engine 에 적재해줍니다. 3. 적재된 정보들은 철저하게 index by index 를 통해 최적화 해줍니다.(일정 기간이 지나면 edge deletion 등)
- 놀랍게도 이 구성들이 2016년, 거의 7여년전 정도에 구상된 아키텍쳐입니다. 물론 지금도 본 아키텍쳐를 활용하고 있으나 이외에도 여러 요소들이 추가 투입되었겠죠. 하지만, 아키텍쳐를 구상하기위해 여러 방면으로 시도하고 왜 그 시도가 채택되지 않았는지 등 시행착오 그리고 노력에 대한 푸념(저에겐 그렇게 보였습니다..하하) 또한 논문에 잘 녹여놓았기에 트위터 알고리즘 역사에 대해 궁금하신 분들에게 재미를 제공할 수 있을거라 생각됩니다.
Insight
- batch processing 과 real-time processing 을 잘 융합하기 위해 어떻게 접근했는지에 대해 잘 표현되어 있기에 이를 중점으로 보시는걸 추천드립니다.
SimClusters: Community-based Representations for Heterogeneous Recommendations at Twitter
[https://github.com/twitter/the-algorithm/tree/main/src/scala/com/twitter/simclusters_v2]
Summary
- 과연 community deteciton 알고리즘이 실제 추천에 효용이 있는가? 라는 의문에 해답을 주는 논문입니다. 기존 matrix factorization 방식은 연산 최적화 문제가 있기에, 이를 해결해보고자 similarity search 와 community detection 을 결합해 그 연산량 절감을 시도한 논문입니다. 그 결과 10~100 배의 속도개선, 3~4배의 성능개선이 이루어졌다고 하네요.
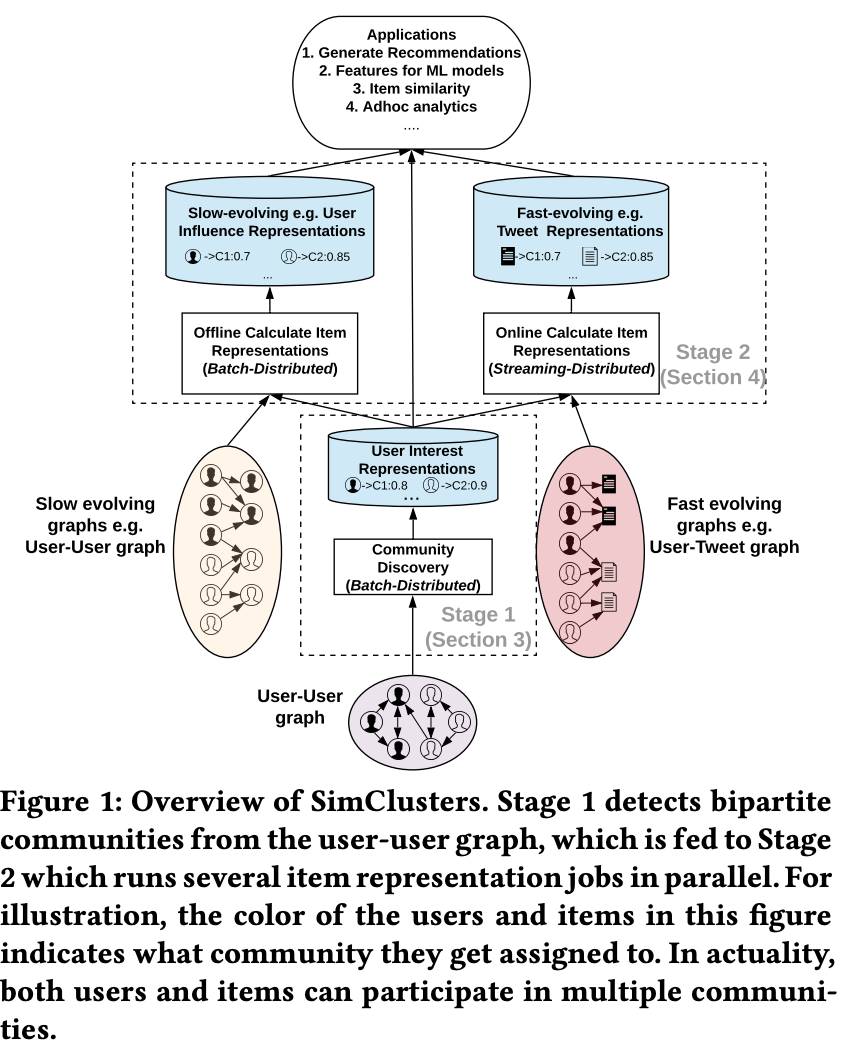
- graphjet 과 동일하게 bipartite graph 에서 추천이 진행합니다. (user-user) 그리고 (user-item) 두가지 bipartite graph 를 활용합니다. 이전과 다르게, A가 B를 팔로우를 했다고해서 B가 자동으로 A를 팔로우되지않는 트위터 SNS 특성을 활용하여 그래프를 directed graph 로 설계해주었다는 점이 약간 다르다고 볼 수 있겠습니다.
- 이렇게, 모델링된 그래프를 다음 3단계를 거쳐 유저에게 추천될 후보군들을 추출하게 됩니다. 1.similarity graph extraction 간단하게 projeciton graph , 1-mode graph 라고 보시면 되겠습니다. 2. community deteciton into simialrity graph 3. 2에서 추출된 community 값을 user feature 로 적용. 이 과정을 통해
- 이외에도, 실시간으로 업데이트 되는 트윗의 hashtag, tweet content등을 item 으로 간주하여 user-item bipartite 그래프에서 커뮤니티를 도출하여 앞선 과정과 유사하게 추천에 적용합니다. 다만 user-user 와 다른점은 user-user 의 관계는 Long-term relationship 이라는 가정을 두었고, user-item은 short-term relationship 을 가정을 두었기에 이를 업데이트하는 주기에 대해 추가로 aggregate function(decay) 를 적용해주었다는 점을 차이점으로 꼽을 수 있겠습니다.
Insight
- 하나하나 다 주옥같은 인사이트들이 담겨있기에, 섣불리 말씀을 드리긴 어려울만큼 좋은 인사이트들이 굉장히 많이 담겨있습니다. 예를 들어, 커뮤니티 디텍션 알고리즘에서 중요한 하이퍼파라미터라고 볼 수 있는 커뮤니티 갯수 선정, 어떻게 matrix factiorzation 을 극복하기, 추천결과를 단순 유저 콘텐츠 추천 뿐만아니라, home page 노출 detail page topic ranking user ranking 등 다양한 application 등이 담겨있기에 시간을 내셔서 한 번 정독해보시는걸 추천드립니다.
- 기존 추천시스템(블랙박스) 와는 다르게 OO 커뮤니티들에 소속되어있어 OO 추천 결과를 도출했다 라는 커뮤니티 디텍션 결과를 통해 추천이 진행되기에 ‘결과에 대한 해석’을 할 수 있다. 라는 점이 굉장히 흥미로웠던 논문이였습니다.
TWHIN : Dense knowledge graph embeddings for Users and Tweets.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
[https://arxiv.org/pdf/2205.06205.pdf]
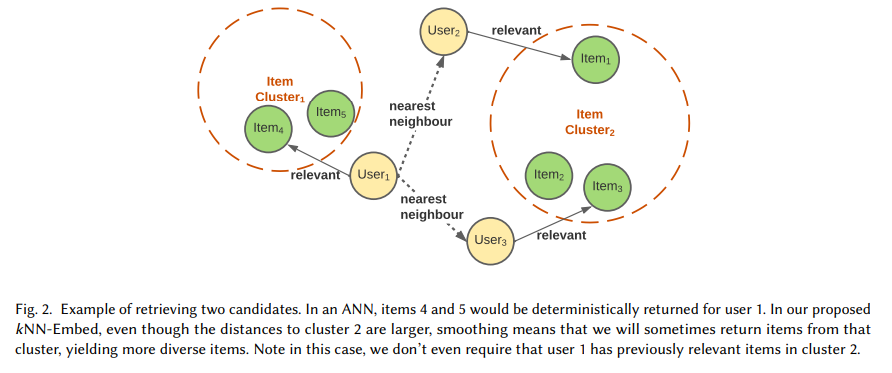
Summary
- 앞선 논문들과 다르게 비교적 간단한 구조를 가지고 있습니다. ANN(approximate nearest neighbor) 를 통해 비슷한 유저들을 추출하고 그 유저들이 어떤 아이템과 상호작용을 나누었는가를 분석하여 그 정보들을 추가로 활용하여 논문을 해주는 작동원리를 가지고 있습니다.
- 이 과정들을 통해 다양한 유저 그래프(user-item distribution)의 distribution 을 mixture 해주기에, diversity 와 Recall 지표측면에서 성능이 향상되었습니다.
Insight
- similar , similar 을 강조하다보면 결국 diversity 문제와 맞닿을수밖에 없습니다. 즉 새로운 아이템들도 추천을 받고싶지만 비슷한 유저들의 특성만을 기반으로 추천이 진행되기에 비슷한 아이템들만 추천되는 문제가 발생합니다. 이는 유저 경험에도 큰 문제로 작용할 수 있죠. 다시 생각해보면 관계에 기반한 추천 , 그래프 추천에서의 고유 문제라고도 볼 수 있는 이 부분을 ANN 을 통해 개선했다는 점이 굉장히 흥미롭습니다. 이 점을 염두하시며, 성능 향상에 톡톡한 역할을 한 smoothed mixture method 를 집중적으로 보시면 어떨까 싶네요.
coffee chat With Katanagraph’s Hadi
주말 이른 아침 그래프 기술을 어떻게 고객에게 잘 전달할 수 있을것인가 라는 주제를 가지고 katanagraph 에서 근무하는 hadi 와 온라인 커피챗을 나누었습니다. Data pipeline 부터 graph analytics 그리고 graph embedding and prediction 까지 all-in-one 으로 활용할 수 있는 platform인 katana-graph 에서 소프트웨어 엔지니어로 근무하고 있기에, 저와 직무 성격이 굉장히 비슷했습니다. 그러기에 1시간이 넘는 시간동안 대화가 끊김없이 이야기를 나눌 수 있지 않았을까 싶네요.
차이점을 꼽자면, on-premise vs. cloud 과 Data injection is important vs. model customizing is important 등 약간 다른 의견을 가지고 있었는데, 서로의 견해에 대한 이야기를 나누며 시야를 넓힐 수 있었기에 굉장히 알찬 시간이였다고 생각됩니다. 이처럼, 그래프를 연구하고 있거나 현업에서 활용하시는 분들중 본인만의 관점에 매몰되었다 생각되어 새로운 관점에 대한 니즈가 있다면 언제든 연락주세요 ! 환영합니다 :)