9월 1주차 그래프 오마카세


Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
[https://arxiv.org/pdf/2306.02592.pdf]
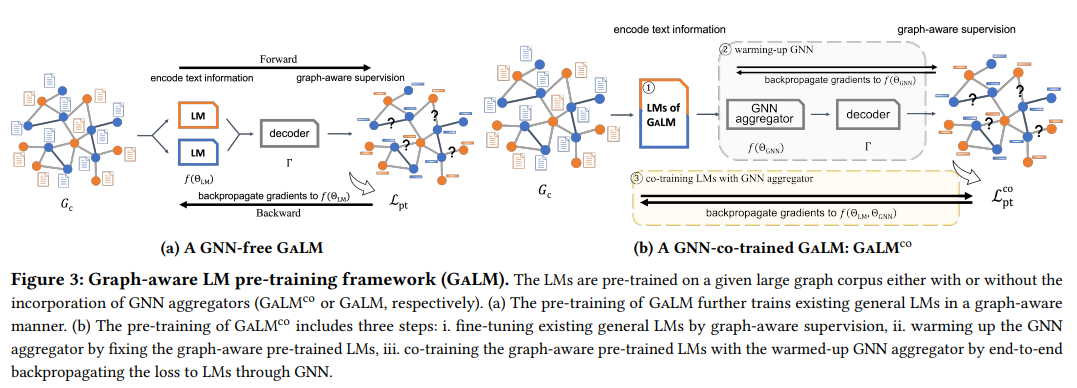
Graph 활용사례들이 늘어가고 있습니다. LLM 및 ChatGPT 흥행의 여파이지 않을까 하네요. 본 논문의 핵심을 말씀드려보자면, 과연 graph topology 를 활용하는게 Application 에 도움이 될까에 대한 원초적인 문제를 기반으로 시작된 논문이라고 할 수 있습니다. 여기에서 Application는 1. Search-CTR 2. ESCvsI 3. Query2PT 3가지 입니다. 모두 유저와 쿼리 그리고 상품간 상호작용을 예측하는 문제라고 할 수 있습니다.
논문을 읽다보니, 주방장은 문득 궁금증이 들었습니다. 굳이 그래프를 왜 여기에..? 라는 궁금증을요. 물론 LLM vs. GALM(our approach) 실험을 통해 그 효과는 입증했지만, 한층 깊게 더 생각해봤습니다. 현업 관점에서 생각해본 결과 아마존에서 굉장히 많은 유저 요청 쿼리 , 상품 그리고 Explicit interaction 이 3가지 요소들을 모두 고려하여 application에 적용하려면, 이 요소들 마다마다의 테이블을 scan 해야합니다. 때문에, 애당초 분석 및 예측 전에 데이터를 불러오는 순간부터 난관에 봉착하니, 그 대안으로 비선형 데이터 자료구조인 그래프를 활용하지않았을까? 라는 결론을 내리니 그 궁금증이 모두 해결되었습니다. 그렇게 형성된 Tabular data → Graph data 에 대한 모델링 방식은 Appendix 에 작성되어있으니, 참조하시는걸 추천드립니다. 모델링 방식과 RGAT, RGCN 두 요소를 결합하여 실험 결과를 바라본다면, 왜 이런 결과가 나왔을까 그리고 topology 가 이럴때 중요하구나 라는 인사이트를 얻으실 수 있습니다.
다시 돌아와서 논문에서는 Pretrained , Fine-tunning 을 적용하며 각각 시도마다 도출될만한 경우의 수들을 모두 실험했습니다. 그 결과 Graph topology 와 LLM 을 접목한 결과가 우수함을 입증합니다. 논문 작성자들 소속이 모두 AWS, Amazon 임을 확인하고 추가로 real-data 를 통해 그래프 모델링 그리고 GNN , LLM까지 적용하였다는것에 많은 의미가 함축되어 있다 생각합니다. Graph를 현업에서 활용하였을 때 가치가 있음을 보여주는 좋은 케이스이기에, 이를 기반으로 다양한 케이스들이 등장할거라 생각되네요. 너무 기쁩니다.
RESIDUAL ENHANCED MULTI-HYPERGRAPH NEURAL NETWORK
[https://arxiv.org/pdf/2105.00490.pdf]
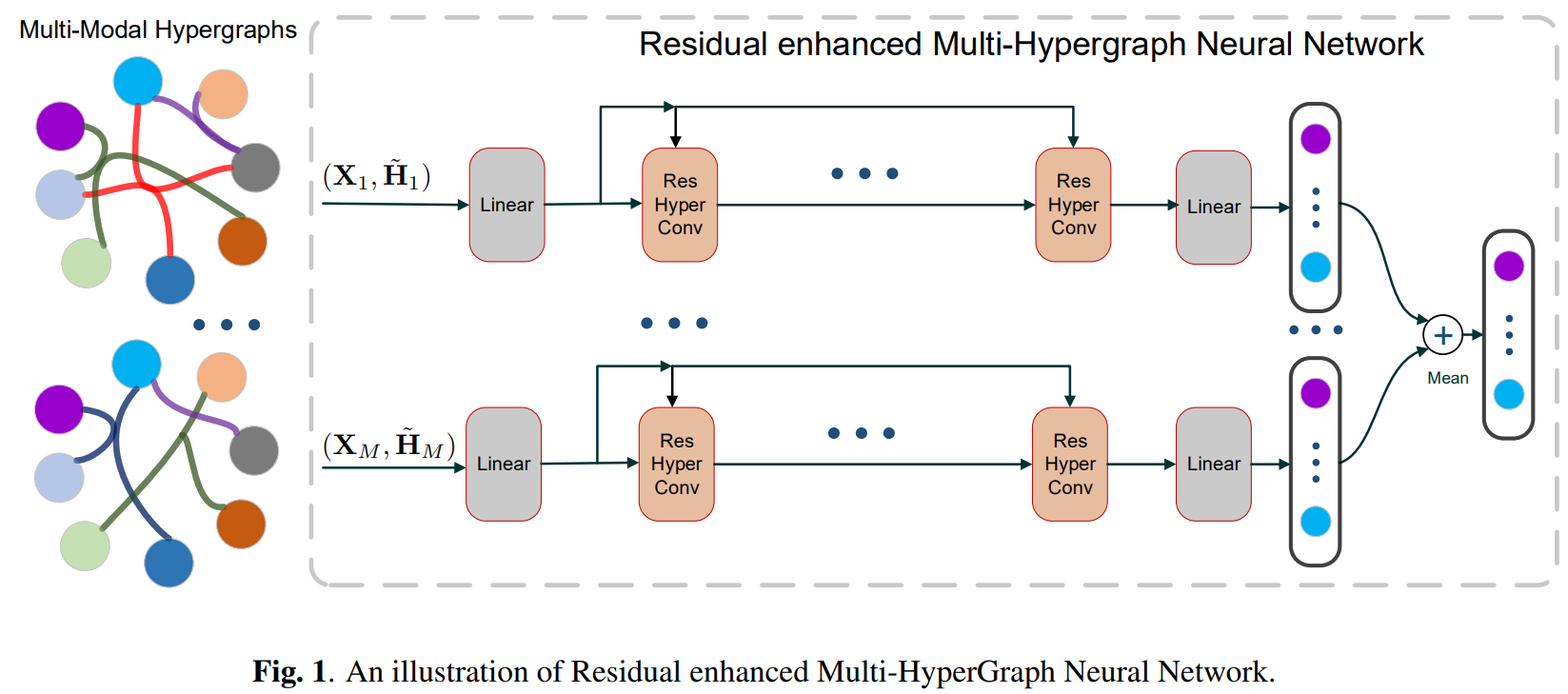
HGNN, HyperGNN pair-wise 론 담아내기에 모자란 관계 및 노드 정보를 확장해서 적용한 group-wise 모델 입니다. 고차원 데이터를 하이퍼엣지라는 요소를 통해 묶어주고 정보 교류를 통해 임베딩을 하는 모델입니다. 기존 pair-wise 모델과 다르게, 노드 그리고 하이퍼 엣지 두 요소 모두 Message passing 이 발생한다는게 큰 차이점으로 꼽을수 있습니다. 여기에서도 정보 교류시 마찬가지로 오버-스무딩 문제가 어김없이 등장합니다. 이 오버-스무딩 문제를 해결하기 위해 Residual-connection 를 활용합니다.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
[https://arxiv.org/pdf/2308.13490.pdf]
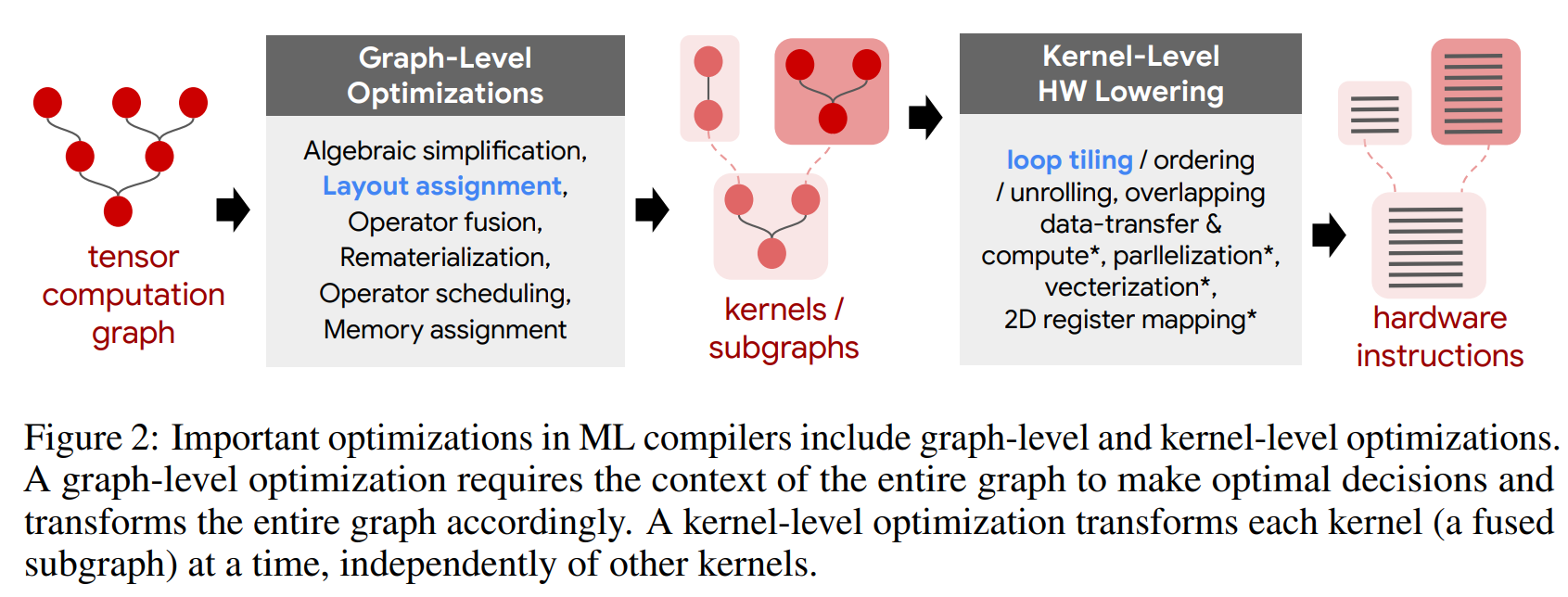
kaggle 플랫폼에서 [https://www.kaggle.com/competitions/predict-ai-model-runtime] 최근 열린 대회입니다. 주어진 계산 그래프를 분석하여 Runtime 이 얼마나 나올지에 대해 예측하는게 과제입니다. 지금 진행하고 있는 대회 개요를 설명하려는게 목적이다보니, 데이터 소개 및 대회 가이드라인 성격이 강한 논문입니다. 데이터에 대한 간략한 소개를 해보자면 layout collection 과 tile collection 2가지 구성으로 나눠져 있으며, 전체 그래프냐 서프 그래프냐로 데이터가 나눠진다고 생각하면 되겠습니다.
대회 베이스라인 모델에 대해 설명을 위해 다양한 모델(LSTM, Transformer, GNN등)을 사용하였는데, 이 중 GNN이 가장 성능이 우수하여 베이스라인으로 지정했다고 합니다. 대회에 참여해서 여러분들의 GNN 모델링 아이디어를 적용해보는것도 물론 좋겠지만, 그러기에 부담이 된다 하시는분들은 논문에서 제시한 Scalability , Disversitty and Imbalance of Graphs, Redundancy 3가지 요소를 어떻게 해결하는지 다양한 참가자들의 아이디어 및 디스커션을 팔로우업 하시는것도 많은 도움이 될거라 생각되어 오마카세 메뉴로 선정했습니다.
특히, 저는 Scability 문제를 해결하기 위해 Entire graph 전체를 메모리에 올리기엔 한계가 존재하니 이를 Graph Segment Training (GST) method 를 활용하여 적용하는게 흥미로웠습니다. 현업에서 대용량 데이터를 학습하기 위해 여러 제한점들이 존재할텐데, 그 제한점들을 해결하는데 도움이 될만한 기술 및 노하우들이 많이 등장할것으로 예상되기에 꼭 대회 디스커션과 코드를 팔로업하시는걸 추천드립니다.