26년 5월 4주차 그래프 오마카세
Random Sets Graph Neural Networks
Random-Set Graph Neural Networks
Uncertainty quantification has become an important factor in understanding the data representations produced by Graph Neural Networks (GNNs). Despite their predictive capabilities being ever useful across industrial workspaces, the inherent uncertainty induced by the nature of the data is a huge mitigating factor to GNN performance. While aleatoric uncertainty is the result of noisy and incomplete stochastic data such as missing edges or over-smoothing, epistemic uncertainty arises from lack of knowledge about a system or model (e.g., a graph’s topology or node feature representation), which can be reduced by gathering more data and information. In this paper, we propose an original new framework in which node-level epistemic uncertainty is modelled in a belief function (finite random set) formalism. The resulting Random-Set Graph Neural Networks have a belief-function head predicting a random set over the list of classes, from which both a precise probability prediction and a measure of epistemic uncertainty can be obtained. Extensive experiments on 9 different graph learning datasets, including real-world autonomous driving benchmarks as such Nuscene and ROAD, demonstrate RS-GNN’s superior uncertainty quantification capabilities
- 여러분이 오랜 시간 공들여 설계한 GNN 모델이 있다고 가정해 보겠습니다. 모델을 실제 문제에 적용해 좋은 결과를 얻었고, 이제는 추가 개선이나 운영 환경 배포를 검토하는 단계에 와 있습니다.
- 여기에서 한 가지 질문이 있습니다. "그 모델이 내놓는 예측이 얼마나 확실한지, 여러분은 알고 있습니까?" 그 모델의 정확도 수치는 알고 계실 겁니다. 하지만 이 예측 결과는 학습 데이터와 비슷한 상황에서 나온 것인지, 모델이 처음 보는 패턴이라 단지 가장 가능성이 높아 보이는 클래스를 선택하여 성능을 높혀낸 건지를 명확하게 구분할 수 있는 방법을 알고 계신가요?
- 대표적인 예시로 금융 사기 탐지 문제에 대해서 GNN이 수백만건의 거래 네트워크를 분석하여 그 계좌가 사기라는 결과를 예측해 냈습니다.
- 하지만 그 판단이 학습 데이터에서 수천 번 반복해 본 전형적인 패턴에서 나온 것인지, 아니면 학습 중 한 번도 보지 못한 새로운 유형의 사기 수법이라 그냥 가장 가능성이 높아 보이는 쪽을 찍은 것인지를 모델 스스로가 구별해낼 수 있어야 합니다. 이 차이를 모르면 언제 사람의 검토가 필요한지 판단할 수 없고, 새로운 사기 유형은 오히려 놓치게 될 것입니다.
- 대부분의 모델은 소프트맥스 출력의 확률 합이 항상 1이 되도록 설계되어 있습니다. 그 결과, 학습 과정에서 한 번도 보지 못한 이상한 입력이 들어오더라도 마치 확신에 찬 것처럼 특정 클래스를 선택하는 경우가 많습니다. 즉, 모델이 모든 상황에서 과도한 자신감을 보일 수 있다는 것이며 우리의 GNN 역시 예외가 아닙니다.
💡
잘 모르겠다"는 답을 낼 수 있는 구조 자체가 없는 것이 문제. GNN 모델도 모를 때는 잘 모르겠다라고 말할 수 있어야 한다. RS-GNN의 제안 목표입니다.
- 이번 주 그래프 오마카세로 전달해드릴 논문은 "GNN의 예측 결과가 얼마나 믿을 만한가?" 를 어떻게 측정할 것인지의 신뢰성 정량화 문제를 다루고 있습니다. 다음 문제는 사실 GNN 뿐만 아니라 대부분의 딥러닝 모델이 반드시 검토해야 할 중요한 부분이라고 생각합니다.
- 핵심 아이디어는 꽤 단순합니다. 불확실성을 확률이 아닌 집합으로 표현하면, GNN이 언제 틀릴지 스스로 알 수 있다는 것입니다. 즉, 확률 하나로 예측을 표현하는 대신, 확률의 범위(하한~상한)로 예측을 표현하자는 것입니다.
- 수십 년간 별개의 영역에서 발전해온 집합과 확률이론을 GNN 모델과 접점을 찾고 통합해보려는 시도는 참신하다고 생각됩니다. 위의 가벼운 예시와 같이 금융 사기, 추천 시스템, 의료 진단 등 틀리면 매우 심각한 결과를 낳는 분야에서 활용되는 우리의 모델이 언제 자신의 판단을 믿어도 되는지를 알려줄 수 있어야 합니다. 위 논문은 그 메커니즘을 구체적으로 제시한다는 측면에서 읽어볼만한 가치가 있다고 생각합니다.
- 불확실성에는 크게 두 가지 종류가 존재합니다.
- 우연전 불확실성 (Aleatoric Uncertainty)는 데이터 자체가 노이즈하거나 불완전해서 생기는 불확실성으로, 데이터를 아무리 더 모아도 줄일 수 없습니다.
- 인식론적 불확실성(Epistemic Uncertainty)은 모델이 지식이 부족해서 생기는 불확실성으로, 더 많은 데이터와 학습으로 줄일 수 있습니다. RS-GNN이 집중적으로 다루는 것은 이 부분, 학습 때 충분히 보지 못했다는 신호를 어떻게 포착하고 측정하는가에 포커스를 둡니다.
- 기존 GNN의 출력은 각 클래스에 대한 확률 값 하나입니다. 이것을 점 예측(point prediction)이라고 합니다. (B라는 스칼라 값으로 출력하는 것) 이러한 점 예측에서 구간 예측(probability intervals)으로 바꾸고자 합니다. (대략 A~C사이라고 말하는 것)
- 구간 예측의 구간을 어떻게 설정할 것인가? 위 논문에서는 믿음 함수 (Belief Function)라는 수학적 도구를 사용합니다. 해당 함수는 개별 클래스 뿐 아니라 클래스 부분집합에 확률 질량(probablility mass)를 배분할 수 있습니다. (A에 0.6, A 또는 B에 0.3, 모르겠다에 0.1의 확률 질량을 배분. A 또는 B에 많은 질량이 쌓일수록 모델이 현재 예측에 헷갈리고 있다고 해석할 수 있습니다.)
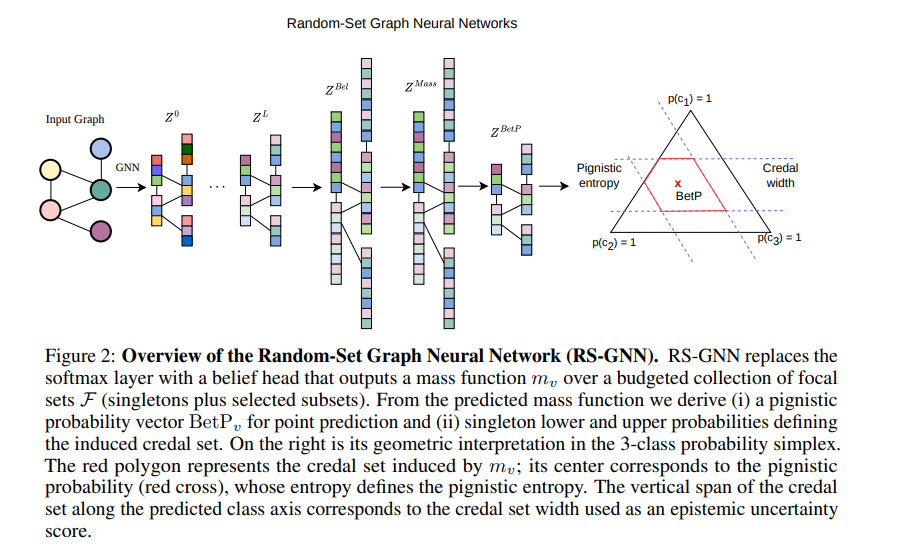
- RS-GNN의 구조는 기존 GNN과 크게 다를 것이 없습니다. 다만 소프트맥스 레이어 하나만을 적절한 대체 레이어로 교체합니다. 해당 레이어를 Beleif Head라고 합니다.
- Belief Head는 각 노드에 대해 Focal Set이라 불리는 클래스 부분집합들의 목록에 확률 질량을 배분합니다. 여기에서 Focal Set은 'A 단독 또는 B 단독' 같은 단일 클래스부터 "A 또는 B"와 같은 복수 클래스 조합까지 포함합니다. 이 때의 계산 효율성을 위해 전체 부분집합을 모두 사용하지 않고 Budget을 정해 상휘 64개의 조합만을 사용합니다.
- 믿음 함수로 예측의 범위를 설정했다면, 실제로 어떤 클래스인지를 나타내는 단일 출력도 뽑을 수 있어야 합니다. 이를 위해 저자들은 Pignistic Transform(피그니스틱 변환)을 사용합니다.
- 해당 변환은 간단하게 말하면, 복수 클래스에 배분된 질량을 해당 클래스 수로 균등 분할해서 더해주는 방식입니다.
- "A 또는 B"에 0.3이 배분되었다고 하면 A와 B 각각에 0.15를 추가합니다. 이렇게 만들어진 BetP_v (식 5 참조)가 RS-GNN의 최종 예측확률이 되고, 가장 높은 클래스가 예측으로 출력됩니다.
- 또한 RS-GNN은 각 그래프 노드에 대해 두가지 불확실성(예측, 인식론적) 지표를 동시에 계산합니다.
- 예측 불확실성(Predictive uncertainty)의 Pignistic Entropy (피그니스틱 엔트로피)는 BetP 확률 분포의 Shannon 엔트로피로 전체적인 예측 불확실성을 측정합니다. 분포가 고르게 퍼져 있을수록(어느 클래스인지 모르는 상태) 높은 값이 나옵니다.
- 다음은 기존 GNN의 softmax 엔트로피와 비슷한 역할이지만, 믿음 함수를 거쳐 더 정교하게 조정된 버전입니다.
- 인식론적 불확실성(Epistemic uncertainty)은 Credal Width 개념을 도입하며, 이는 예측 클래스에 대한 확률의 상한 및 하한의 차이(Plausibility - Belief)입니다. 엔트로피가 "전반적으로 헷갈린다"를 측정한다면, Credal Width는 "이 특정 예측에 대해 얼마나 모르는가"를 측정합니다.
- 이 값이 클수록 "이 노드의 클래스에 대해 구체적으로 얼마나 확신하는지 모른다"는 의미이며, 학습 때 보지 못한 클래스(OOD 노드)에서 이 값이 크게 올라가는 것이 핵심 작동 원리입니다.
- 예측 불확실성(Predictive uncertainty)의 Pignistic Entropy (피그니스틱 엔트로피)는 BetP 확률 분포의 Shannon 엔트로피로 전체적인 예측 불확실성을 측정합니다. 분포가 고르게 퍼져 있을수록(어느 클래스인지 모르는 상태) 높은 값이 나옵니다.
- 실험은 실제로 OOD 탐지에 효과가 있는지를 평가하고자 하였습니다. 설계의 핵심으로는 학습할 때 일부 클래스를 의도적으로 빼두고, 테스트 때 그 클래스가 등장했을 때 모델이 이건 처음 보는 유형인데? 라고 높은 불확실성을 표시하는지 확인하는 "Leave-Out-Class" 방식입니다.
- 기준 지표는 AUROC으로, 높을수록 ID(정상)와 OOD(이탈)를 잘 구분하는 것입니다.
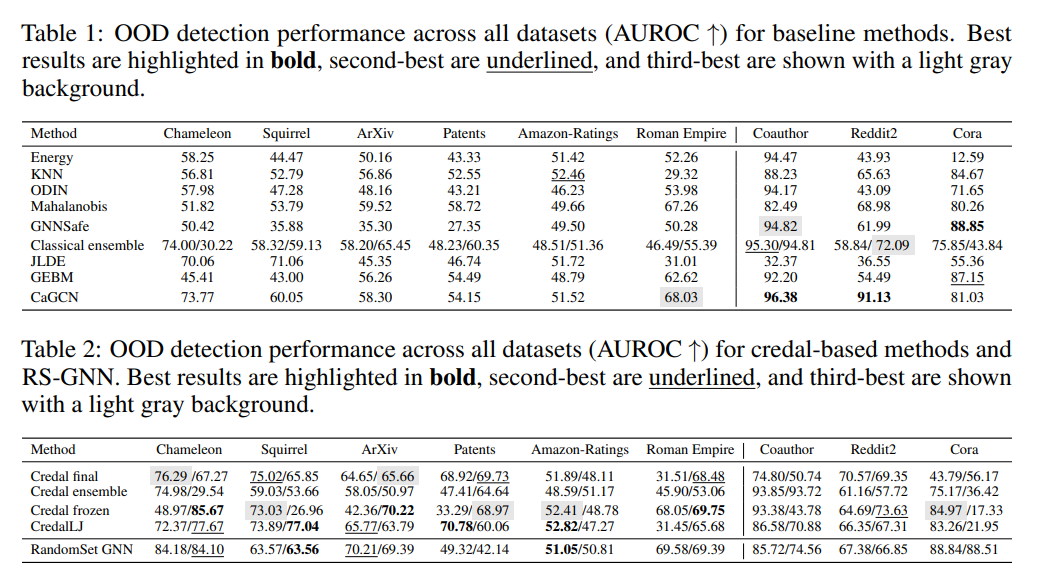
- 총 9개의 그래프 데이터셋에서 실험했으며, 그 중 자율주행 실세계 데이터인 ROAD와 nuScenes 결과가 특히 주목할 만합니다. nuScenes의 결과를 보면, Vanilla GNN에서는 OOD 노드와 ID 노드의 softmax 엔트로피가 거의 차이가 없어서, OOD 탐지가 사실상 불가능한 수준(AUROC 0.463)이었으나 RS-GNN은 Credal Width 기반으로 AUROC 0.521을 달성하며 의미 있는 불확실성 신호를 유지합니다.
- 절대적인 수치만 보면 높다고 보기 어렵지만, 기존 GNN이 사실상 무작위 수준으로 붕괴한 상황에서도 의미 있는 불확실성 신호를 유지했다는 점에 의미가 있습니다.
- 다음 결과를 통해 기존 GNN은 처음 보는 클래스에도 높은 자신감을 유지하고 있었지만 RS-GNN은 그 상황에서 어라, 이건 조금 낯선 상황같은데? 라는 신호를 보낸다는 사실을 확인할 수 있습니다.
- ROAD 데이터셋으로 학습하고 nuScenes 데이터셋에서 테스트하는 크로스 도메인 실험이 가장 어렵지만 인상적인 시나리오입니다. Vanilla GNN은 AUROC가 거의 0에 가깝게 붕괴하며, 완전히 다른 도메인의 노드에도 높은 확신을 보이는 현상이 나타납니다. RS-GNN은 절대적인 성능은 낮지만 이 완전 붕괴를 피하며 부분적인 불확실성 신호를 유지합니다.
- Focal-set selection, Training objective, hyperparameters 등의 Ablational study에서는 RS-GNN의 성능이 특정 최적화 선택보다 대부분 믿음 함수의 표현 자체에서 나온다는 것을 확인할 수 있습니다. 즉 표현의 구조가 핵심이라는 것을 내포합니다.
- RS-GNN의 가장 큰 가치는 기존 GNN 파이프라인에 최소한의 변경으로 불확실성 정량화를 추가할 수 있다는 점입니다. 인코더는 그대로 두고 출력 헤드 하나만 교체하면 되기 때문에, 이미 학습된 모델 위에 얹는 방식으로도 적용이 가능합니다. 앙상블 방법처럼 모델을 여러 개 학습시킬 필요가 없고, 베이지안 GNN처럼 복잡한 사전분포를 설계할 필요도 없습니다.
- 1990년대 연구된 믿음 함수의 전파(belief propagation)와 2000년대 GNN의 핵심 메세지 전달 연산과는 사실 수십 년간 각자의 방식으로 발전해온 분야입니다. 이 두 독립적인 전파 이론이 GNN에 연결될 수 있다는 놀라운 사실을 보여주기도 합니다.
- 논문 결론에서 "다음 단계는 메시지 전달 자체에 믿음 함수를 통합하는 것"이라고 명시할 만큼, 이 방향의 확장 가능성은 넓습니다. 그래프 연구자의 관점에서 보더라도 앞으로 탐구하고 개척할 수 있는 연구 주제가 폭넓게 남아 있음을 확인할 수 있습니다.
- 한계점은 없을까요.
- 첫째, 크로스 도메인 시나리오(ROAD→nuScenes)에서는 RS-GNN도 절대 성능이 낮습니다. 즉, 도메인 자체가 너무 다를 경우 불확실성 신호가 충분히 크게 올라가지 않는 문제가 있습니다.
- 둘째, 분류 정확도와 OOD 탐지 성능이 항상 함께 좋아지지는 않습니다. 어떤 설정에서는 ID 정확도가 높은 쪽이 OOD 탐지에서 더 약한 경우도 있습니다. 이는 정확도 최적화만으로는 불확실성 인식 모델을 평가하기 부족함을 보여줍니다.
- 셋째, 클래스 수가 많아질수록 Focal set의 조합이 기하급수적으로 늘어나는 스케일링 문제가 있습니다. 논문에서는 budget 기반 focal set 선택으로 이를 완화하지만, 수백 개 이상의 클래스를 다루는 환경에서의 동작은 추가 연구가 필요합니다.
- 전체적인 내용을 정리해보자면, 이 논문은 GNN 연구가 언제 예측을 믿어도 되는가?라는 신뢰적 질문을 깊게 다루는 방향으로 나아가고 있음을 보여줍니다. 실제 문제에 대한 응용 및 배포 모델을 준비중이시라면 불확실성 정량화는 선택이 아니라 필수 설계 요소로 고려해보셔야 할 것입니다.
- AI의 신뢰성은 단순히 높은 정확도가 아니라, 자신이 무엇을 알고 무엇을 모르는지를 구분할 수 있는 능력에서 결정될지도 모릅니다. RS-GNN은 GNN 한정 모델이 이 능력을 갖출 수 있는 가능한 방향을 제시하며, 이론과 실용의 균형 측면에서 충분히 참고할 만한 인사이트를 제공하고 있다고 생각됩니다.
References
- Aleatoric vs. Epistemic Uncertainty 구분 : https://arxiv.org/abs/1910.09457
- 믿음 함수의 이론적 이해: https://www.geeksforgeeks.org/machine-learning/ml-dempster-shafer-theory/
- Pignistic Transform이란 : https://en.wikipedia.org/wiki/Pignistic_probability
- Credal Set과 Credal Width이란 : https://www.emergentmind.com/topics/credal-sets
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184