24년 9월 3주차 그래프 오마카세
Graph Inductive Biases in Transformers without Message Passing
paper link & official code : https://paperswithcode.com/paper/graph-inductive-biases-in-transformers
배지훈
Index
- (Methodology) Learned Random Walk Relative Encodings
- (Methodology) Flexible Attention Mechanism with Absolute and Relative Representations
- (Methodology) Injecting Degree Information
- Experiment Results
- 이번 주 오마카세에서는 그래프 트랜스포머와 관련한 재밌는 논문 하나를 전달해드리고자 합니다. 논문의 이름 그대로, 메세지 전달 메커니즘을 활용하지 않고 그래프 트랜스포머 모델에 Graph inductive bias를 통합할 수 있는 기법을 제안합니다.
- 다들 잘 아시다시피 모델의 일반화 측면에서, 다음 inductive bias 개념은 정말 중요합니다. 다음의 정의로부터 주어진 데이터로부터 추출된 정보들로부터 습득되어진 추가 지식을 통해 새로운 테스트 데이터의 정확한 예측에 도움을 줄 수 있기 때문입니다.
- 대표적인 그래프의 (relational) inductive bias로는 permutation equivariance / invariance가 있습니다. 기존 MPNNs은 메세지 전달 메커니즘을 통해서 다음 inductive bias를 통합할 수 있으나, over-smoothing 등과 같은 고질적인 문제에 어려움을 겪습니다.
- 그로부터 등장한 그래프 트랜스포머는 기존 트랜스포머의 그래프 도메인으로 특정한 어텐션 메커니즘 학습을 통해 MPNNs의 문제점을 완화하고 성능 향상을 이루어낼 수 있었습니다. 하지만 트랜스포머 모델은 해당 도메인의 강력한 inductive bias를 가지고 있지 않다는 사실이 널리 알려져있으며 일반화 및 모델 강건성을 보장하기 위해 거대한 학습 데이터셋이 요구될 수 있습니다.
- 그래프 각 노드와 모든 노드들와의 관계를 어텐션 연산을 통해 계산하는 그래프 트랜스포머 모델 역시 Graph inductive bias가 작을 수 밖에 없습니다. 따라서 작은 크기의 데이터셋의 학습 환경에서는 다음 bias를 잘 활용하는 MPNNs보다 좋지 않은 성능을 보이는 경우도 존재합니다.
- 그로부터 모든 노드들이 아닌, 지역적 이웃 노드들에서만 어텐션 집계를 활용하고자 하는 식의 메세지 전달 기반 그래프 트랜스포머를 제안하는 연구들이 많이 등장하였습니다. 다음의 공통적인 한계점은 over-smoothing 등의 MPNNs의 문제점을 그대로 상속받아버리며, 트랜스포머의 기본 메커니즘과 다르기 때문에 관련 도메인으로의 확장성이 제한되어버립니다.
- 이러한 Trade-off 관계를 한번에 타파할 수 있는 모델을 다음 논문에서 제시합니다. 핵심 아이디어를 요약하자면, 논문의 이름 그대로 메세지 전달 메커니즘에서 벗어나 MPNNs의 한계점을 피하면서 Graph inductive bias이 부족한 기존 그래프 트랜스포머의 한계점을 극복하는 모델, Graph Inductive bias Transformer (GRIT)을 설계하는 것이 되겠습니다.
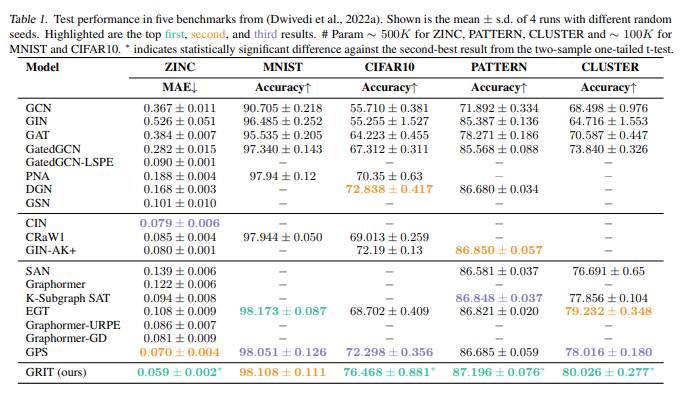
- Small & large graph classification & regression benchmark benchmark 데이터셋에서 진행한 폭넓은 실험 결과에서 제안 GRIT는 뛰어난 성능을 꾸준히 달성할 수 있음을 보입니다.
Methodology
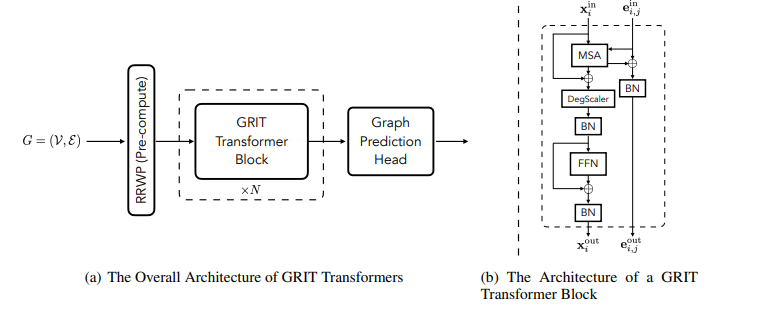
- Graph inductive bias를 통합하기 위해 저자들은 크게 3가지 설계 방법을 제시합니다. 다음은 아래와 같습니다.
- Learned Random Walk Relative Encodings
- Flexible Attention Mechanism with Absolute and Relative Representations
- Injecting Degree Information
- Learned Random Walk Relative Encodings
- 그래프 트랜스포머는 일반적으로 각 노드를 토큰화하여 임베딩하고 어텐션 연산 및 FFNs 모듈을 통해 이를 업데이트합니다. 즉, 토큰화 과정에서 그래프 구조 정보가 손실되기 때문에 이를 보완하기 위한 적절한 위치 인코딩 모듈이 반드시 필요합니다. 대표적으로 Graphormer 논문에서는 spatial positional encoding을 위해 Shortest-path distance (SPD)를 활용합니다.
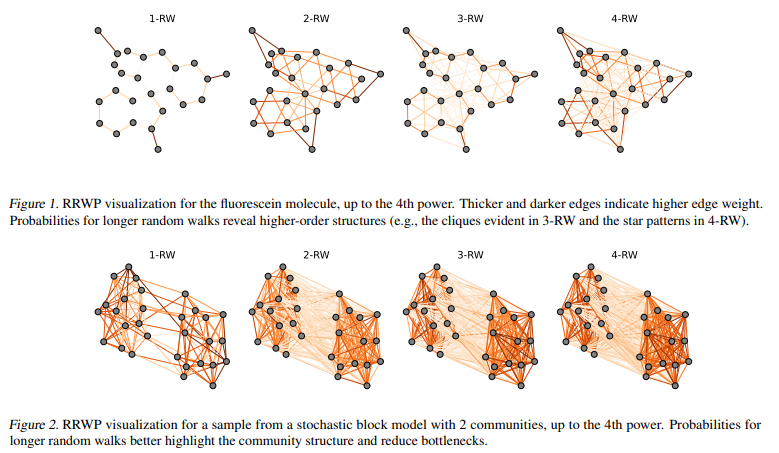
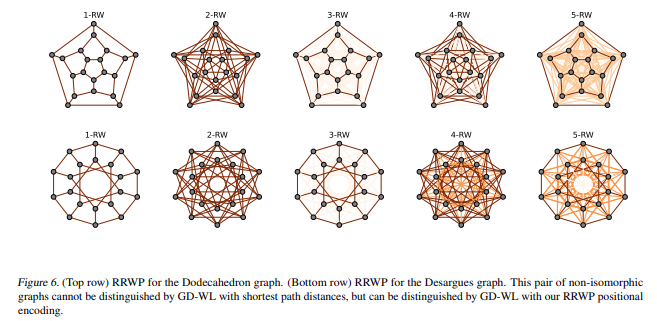
- 다음 논문에서 저자들은 랜덤워크 확률성에 대한 이론적인 정당성을 제공함으로써, 새로운 위치 인코딩 방식으로 relative random walk probabilities (RRWP) initial positional encoding을 제안합니다. 다음은 MLP를 추가적으로 통과시켜 요소별 업데이트를 수행한 새로운 상대적 위치 정보를 출력하며, 결과적으로 기존 SPD 기반 위치 인코딩 방식의 표현력을 능가할 수 있음을 입증합니다. (Fig 1, 2 참고)
- RRWP 기반 초기 위치 인코딩은 두 노드 (i,j) 쌍에 대하여 랜덤워크 행렬 (M = D-1A)을 기반으로 아래의 식 1과 같이 정의됩니다. 다음은 기존 Random Walk Structural Encodings (RWSE) 방식과 일치합니다.
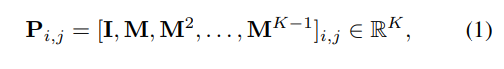
- 여기에서 저자들은 학습된 P 정보를 활용하기 위해, 식 1의 각 요소별로 MLP를 각각 통과시켜 새로운 위치 인코딩 벡터를 얻어냅니다. MLP 네트워크로 학습시킨 랜덤워크의 무작위성을 제한시켜 Expressive power에 중요한 Propagation matrices를 찾아낼 수 있게 되며, 그로부터 유용한 Graph inductive bias를 제공할 수 있음을 해당 논문의 Proposition 3.1에서 설명합니다. 또한 다음의 시각화 결과를 Fig 1,2에서 보이고 있습니다.


- Proposition 3.1에서 언급하는 것은, RRWP + MLP의 구조를 통한 학습된 상대적 위치 인코딩의 활용은 위의 (a~c)의 근사화 효과를 얻어낼 수 있다는 것입니다. 다음에 대한 증명은 Appendix C.2에서 자세히 전개하여 보여주지만, 다음 오마카세에서는 다루지 않겠습니다.
- (a)는 최대 K-1 홉만큼 떨어진 노드들을 고려한 모든 SPD 정보를 포착할 수 있음을 나타냅니다.
- (b)는 각 노드마다 최대 k번 반복적으로 집계되는 랜덤워크 행렬 (: Propagation matrix) 을 활용하는 모든 모델 (e.g. K-truncated PageRank, K-truncated Heat kernels)을 일반화할 수 있음을 나타냅니다.
- (c)에서는 GCN-based 모델 또한 일반화할 수 있음을 나타냅니다.
- (a~c)의 일반화 가능성을 통해 제안 RRWP + MLP 위치 인코딩 방법은 다양한 graph propagation 방법들을 통합할 수 있게 되며, 그로부터 강력한 Graph inductive bias를 제공할 수 있다는 이점을 갖게 됩니다.
- Flexible Attention Mechanism with Absolute and Relative Representations
- 어텐션 연산의 효율성을 극대화하기 위해, 저자들은 그래프 노드 자체의 표현 뿐만 아니라 (Absolute), 노드 간 연결을 인코딩하는 엣지에서의 상대적 표현정보 (Relative)까지도 폭넓게 활용하는 새로운 어텐션 메커니즘을 제안합니다. 아래의 식 2와 같이 정의됩니다.
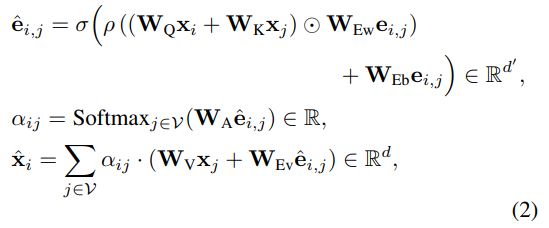
- 여기에서 x_i,j 및 e_ij 벡터는 각각 노드 및 엣지 피쳐 벡터에 위의 RRWP+MLP의 위치 인코딩 벡터를 concat하여 합친 초기 입력 노드 및 엣지 벡터를 의미합니다.
- 그리고 W는 각각에 대한 가중치 행렬을, \Rho 표기는 거대 데이터셋에서의 안정된 학습을 위한 signed-square-root {:= (ReLU(x))1/2 −(ReLU(−x))1/2}을 의미합니다.
- 다음 어텐션 연산 과정은 (RRWP+MLP로 학습된 초기) 엣지 표현정보를 활용하여 어텐션 스코어를 학습하고 연결된 노드를 업데이트하기 때문에 더욱 유연한 위치 정보의 변화에 대응할 수 있다는 이점을 가지고 있습니다. 이 또한 유용한 Graph inductive bias 획득에 큰 영향력을 행사하게 됩니다.
- 멀티헤드 어텐션 기법을 활용하여 얻어낸 노드 및 엣지 표현정보는 아래와 같습니다.
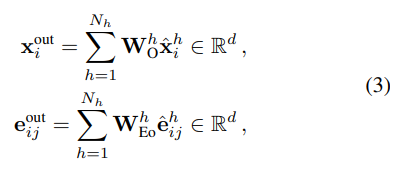
- Generalized Distance Weisfeiler-Leman (GD-WL) graph isomorphism test에서 Fig 3의 그래프에 대한 SPD 방식의 표현력을 능가할 수 있음을 보입니다. (Fig 6 참고)
- Injecting Degree Information
- 마지막으로 저자들은 식 3의 xout에 차수 정보를 추가하여 어텐션 메커니즘의 차수 정보를 보존할 수 있도록 설계합니다. 트랜스포머 모델의 설계 방식과 동일한 FFN 네트워크를 통해 업데이트된 xout'을 얻어내며 아래의 식 3과 같이 정의됩니다.
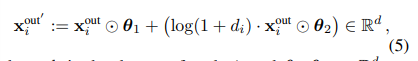
- 세부 설계 방식으로 적절한 차수 정보를 포함하기 위해, 기존 어텐션 모듈의 layer-norm이 아닌 batch-norm을 사용하였다고 합니다.
Experiment Results
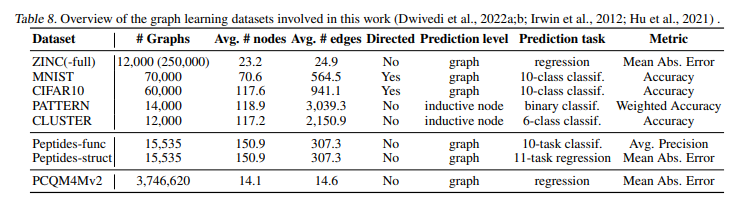
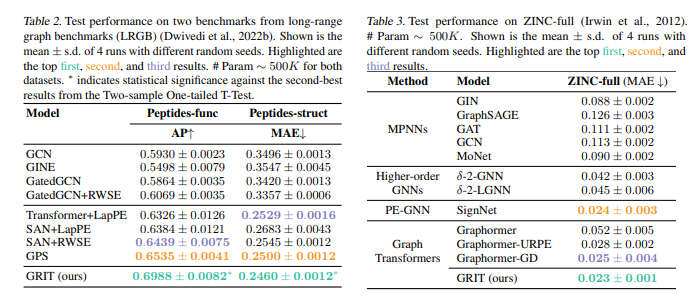
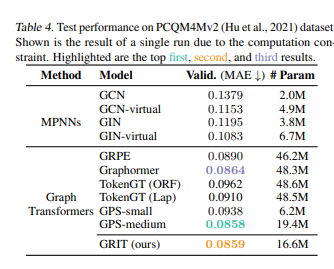
- 어떠한 메세지 전달 과정 (식) 없이, 학습된 랜덤워크 기반 상대적 위치 인코딩을 기반으로 flexible attention mechanism 및 Injected degree information으로 설계된 새로운 그래프 트랜스포머 모델 GRIT를 통해 유용한 Graph inductive biases를 통합하고 기존 방법들의 expressive power를 능가할 수 있다는 사실을 폭넓은 실험을 통해서 입증합니다.
- MPNNs 및 그래프 트랜스포머의 한계점을 잘 보여줄 수 있는 다양한 관점에서의 Small & Large graph classification/regression benchmark 데이터셋에서 제안 GRIT의 consistent한 Sota 성능을 보여줍니다.
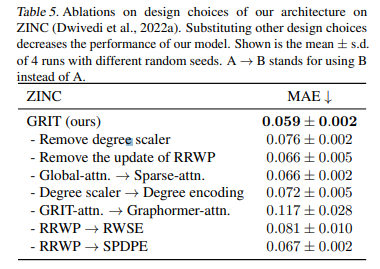
- Ablations 실험에서도 degree scalers 제거, RWSE 위치 인코딩 변경, RRWP 메커니즘 요소 제거 등등의 다양한 환경 요소들에서 실험을 진행하였을 때 최종 GRIT 구조에서의 결과가 가장 좋았다는 사실도 보입니다. 자세한 실험 내용은 해당 논문을 참고해주세요.
- 이번 주 오마카세에서 전달해드린 새로운 그래프 트랜스포머 GRIT 논문에서는 기존 MPNNs의 잘 알려진 문제점 (over-smoothing ..)들을 파생시키는 메세지 전달 메커니즘을 아예 배제하고, 기존 그래프 트랜스포머 계열의 graph inductive bias의 부재를 모두 커버할 수 있는 방법론들을 크게 3가지로 나누어 제안하였습니다.
- 학습된 랜덤워크 기반 상대적 초기 위치 인코딩, 다음 인코딩 벡터들을 초기 벡터에 concat한 노드 및 연결 엣지 표현정보를 모두 활용하는 Flexible attention mechanism, 그리고 차수 정보까지 모두 보존할 수 있다는 이점들로부터 GRIT는 폭넓은 그래프 벤치마크 데이터셋 상의 Classificiation & Regression tasks에서 좋은 성능을 유지할 수 있었습니다.
- RRWP + MLP 방식의 위치 인코딩 방식과, 해당 FFN 모듈 내 Layer-norm 보다 Batch-norm이 제안 아이디어에 더욱 적합한 이유 등을 이론적으로 전개하여 Appendix C에서 자세하게 밝히고 있습니다. 다음 사실로부터 GRIT의 좋은 성능에 대한 신빙성을 충분히 챙겨왔다고 생각합니다. 또한 Fig 1,2 그리고 Fig 6에서 시각적으로 모델 표현력을 확인할 수 있었던 부분도 좋았습니다.
- 한 독자 분의 요청 덕분에 재밌는 논문을 찾아 읽어보고 다른 독자 여러분들께 전달해드릴 수 있었습니다. (감사합니다 !) 앞으로도 그래프 오마카세에서 다뤄보았으면 좋을 것 같은 주제 및 논문 등이 있으면 부담없이 연락 부탁드립니다. 또한 오마카세 연재에 관심이 있으신 분들께서도 언제든지 자리가 열려있으니 연락 부탁드립니다.
- 긴 글 읽어주셔서 감사합니다, 다들 즐거운 추석 연휴 보내시길 바랍니다 !
[Contact Info]
Gmail : jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
Neo4j CEO 가 언급한 GraphRAG 영상부터 네이버 지식그래프 , 온톨로지 구축 그리고 Knowledge Graph , GNN application 영상까지!
정이태
메리 추석입니다! 다들 본가로 돌아가서 가족분들과 즐거운 명절을 지내고 계신가요? 저는 집에서 유튜브 알고리즘의 인도...?에 의해 Neural scaling 영상부터 Neo4j CEO 가 최근 AiEngineer conference에서 GraphRAG 대해 발표한 영상을 보면서 연휴를 보내고 있네요. 평소 GraphRAG가 궁금하셨던 분들이 보면 좋을 영상이네요.
Search engine 의 시초 text search 부터 (당시) PageRank 기술을 기반으로 검색 엔진계에 신흥 강자로 등장한 구글, 그리고 Page Rank 는 결국 그래프 형태이며 지식그래프에 대한 언급 그리고 현재 GraphRAG + LLM 의 시대까지 왔다 라는 흐름을 설명합니다.왜 지금 어딜가나 GraphRAG 라는 단어가 나오는지 명쾌하게 잘 풀어놓았기에, 그 배경을 살펴보시기에 좋습니다.
GraphRAG가 왜 좋은지를 1. 정확도 향상 2.쉬운 배포 및 개발 3. LLM output을 설명가능하다 3가지 이유를 간단 명료하게 짚고 넘어갑니다.마지막엔 Unstructured , Structured , Semi-structured data를 drag&drop을 통해 그래프가 만들어지는 데모로 발표를 마칩니다. (이때, Neo4j cloud disconnection 이슈가 발생합니다.. 발표 끝나고 관련 담당자들이 어떻게 됐을지 하하..생각만해도 아찔하네요.)
여기서 잠깐, 서두에 언급한 지식그래프를 우리 나라의 검색 엔진 분야에선 어떻게 활용하고 있을까? 라는 호기심이 생기신 분들을 위해 재밌는 자료도 추가로 공유드립니다. Deview에서 발표한 자료 및 영상입니다.
영어로는 온톨로지 구축 자료를 많이 봤는데 한국어로는 과연 온톨로지를 어떻게 구축할까? 라는 궁금증이 있으셨던 분들이 보셔도 많은 도움이 될 거에요. 또한, 온톨로지 구축시에 늘 마주하게 되는 Record linkage , Entity Resolution 을 어떤식으로 해결하는지! SimRank 알고리즘 , block 과 meta를 연계짓는 개념 등 재밌는 아이디어들이 많아요.
이렇게 지식그래프를 잘 구축한 다음에 어떤식으로 활용하는지 지식그래프 검색과 영상의 맛집 추천을 위한 Knowledge Graph 그리고 GNN 까지 이어서 보시면 이론부터 Real-world application case 까지 핵심적인 내용을 보셨다고 해도 무방할 거 같아요.
지식그래프 구축을 고민하고 있는 현업에 계신분들 혹은 연구를 위해 온톨로지에 대해 스터디 하고 계시는 분들 모두 도움이 될 자료이기에 한 번 살펴보시는걸 추천드려요!어쩌다가 연휴에 그래프 영상보고 좋은 자료길래 공유드리려고 했다가 네이버 지식그래프 자료까지 전달드리게 되었네요.
하하 .. ! 도움이 되셨기를 바랍니다. 그럼 오늘도 즐거운 하루 되시고, 연휴 잘 보내시길 바라겠습니다! :)
1.Stella NAVER 통합 Knowledge Graph
2.Knowledge Graph에게 맛집과 사용자를 묻는다. : GNN으로 맛집 취향 저격 하기

3.본문에서 언급한 Neo4j CEO GraphRAG 발표영상
GraphRAG: The Marriage of Knowledge Graphs and RAG: Emil Eifrem